1. 项目介绍
跨模态文档问答是跨模态的文档抽取任务,要求文档智能模型在文档中抽取能够回答文档相关问题的答案,需要模型在抽取和理解文档中文本信息的同时,还能充分利用文档的布局、字体、颜色等视觉信息,这比单一模态的信息抽取任务更具挑战性。
这种基于跨模态文档阅读理解技术的智能问答能力,可以深度解析非结构化文档中排版复杂的图文/图表内容,直接定位问题答案。
本项目将基于跨模态文档问答技术实现汽车说明书问答系统,该系统能够对用户提出的问题,自动从汽车说明书中寻找答案并进行回答。
如图1所示, 用户提出问题:“如何更换前风窗玻璃的刮水片”,跨模态文档问答引擎将从库中寻找相关的文档,然后通过跨模态阅读理解模型抽取出相应的答案,并进行了高亮展示。

通过使用汽车说明书问答系统,能够极大地解决传统汽车售后的压力:
用户:用户没有耐心查阅说明书,打客服电话需要等待
售后客服:需要配置大量客服人员,且客服专业知识培训周期长
构建问题库:需要投入大量人力整理常见问题库,并且固定的问题库难以覆盖灵活多变的提问
对于用户来说,汽车说明书问答系统能够支持通过车机助手/APP/小程序为用户提供即问即答的的功能。对于常见问题,用户不再需要查阅说明书,也无需打客服电话,从而缓解了人工客服的压力。
对于客服来讲,汽车说明书问答系统帮助客服人员快速定位答案,高效查阅文档,提高客服的专业水平,同时也能够缩短客服的培训周期。
2. 安装说明
在开始学习之前,请确保如下运行环境已安装。
!pip install yacs
!pip install paddlenlp2.3.1
!pip install paddleocr2.5
3. 整体流程
汽车说明书问答系统针对用户提出的汽车使用相关问题,智能化地在汽车说明书中找出对应答案,并返回给用户。本项目提供的汽车说明书问答系统的使用流程如图2所示。本项目提供的汽车说明书问答系统主要包括 3 个模块:文档解析模块、排序模块和跨模态阅读理解模块。
在使用汽车说明书问答模型回答问题之前,需要先使用PaddleOCR对离线提供的汽车说明书文档进解析,并将解析结果保存下来,以备后续排序模块使用。
对于用户提问的问题,首先会被传入排序模块,排序模块会针对该问题对解析的文档进行排序打分,其结果将会被传入跨模态阅读理解模块。阅读理解模块将从分数最高的说明书文档中,抽取用户问题的答案,并返回给用户。
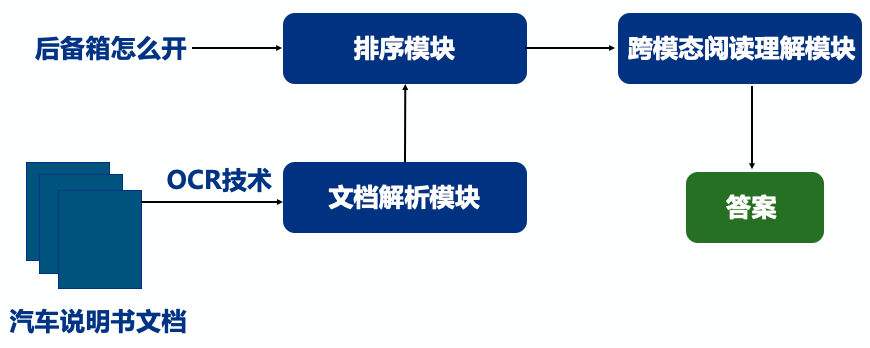
下面将具体介绍各个模块的功能。
4. 文档解析模块
本项目提供了包含10张图片的汽车说明书,为方便后续处理,首先需要通过 PaddleOCR 对汽车说明书进行识别,记录汽车说明书上的文字和文字布局信息, 以方便后续使用计算机视觉和自然语言处理方面的技术进行问答任务。
这10张汽车说明书图片存放至目录存放至 “./OCR_process/demo_pics"下,首先本模块会使用PaddleOCR对汽车说明书进行文档进行初步解析,然后会对解析结果作进一步处理以适合输入至后续的阅读理解模型,生成的结果存放至”./OCR_process/demo_ocr_res.json"中。
本项目文档解析后的结果将包含两个重要的信息: “document” 和 “document_bbox”,如图3所示。
“document”:文档解析模块识别出的文字(token),
“document_bbox”:每个token在汽车说明书上对应的坐标,分别对应(x_min, x_max, y_min, y_max)。

可运行如下命令进行文档解析:
%cd OCR_process
!python ocr_process.py
%cd …
5. 排序模块
对于用户提出的问题,如果从所有的汽车说明书图片中去寻找答案会比较耗时且耗费资源。因此这里使用了一个排序模块,该模块将根据用户提出的问题对汽车说明书的不同图片进行打分排序,这样便可以获取和问题最相关的图片,并使用跨模态阅读理解模块在该问题上进行抽取答案。
5.1 模型训练
本项目提供了140条汽车说明书相关的训练样本,用于排序模型的训练, 同时也提供了一个预先 训练好的基线模型 base_model。 本模块可以使用 base_model 在汽车说明书训练样本上进一步微调。
5.1.1 数据说明
排序模型的训练集文件为./Rerank/data/train.tsv,图4展示了排序模型的汽车说明书训练样本。可以看到,每条样本包含3列数据,分别是:用户问题,文档,标签。其中标签为1表示用户问题的答案出现在了该文档中,标签为0表示用户问题和该文档无关。

备注:汽车说明书的排序模型训练集也可点击这里 手动下载,下载后将其重命名为 train.tsv ,存放至 ./Rerank/data/ 目录下便可。
5.1.2 模型训练
本节将基于 base_model 在汽车说明书的排序数据集上进行微调训练。具体来讲,本节将会对训练集中的用户问题和文档进行拼接,并传入 ERNIE 模型进行二分类任务。
其中,base_model 是 Dureader retrieval 数据集训练的排序模型, 可使用如下命令下载:,下载完成后,将其解压至./Rerank/checkpoints 目录后,便可以获得该模型。
下载和解压代码实现如下:!mkdir -p ./Rerank/checkpoints
!wget https://paddlenlp.bj.bcebos.com/models/base_ranker.tar.gz
!tar -xzvf base_ranker.tar.gz -C ./Rerank/checkpoints/
然后使用如下命令,便可以开始模型训练:%cd Rerank
!bash run_train.sh ./data/train.tsv ./checkpoints/base_model 50 1
%cd …其中,参数依次为训练数据地址,base_model 地址,训练轮次,节点数。
在训练过程中,会将模型存放至目录./Rerank/output下。训练结束后选择合适的模型移动至./checkpoints/ 目录下,并正式重命名为ranker。
可以使用如下命令进行实现:
%cd Rerank/
%mv output/step_201 checkpoints/
%mv checkpoints/step_201 checkpoints/ranker
%cd …
5.2 模型测试
在模型训练完成后,便可以开启模型测试。本节将实现根据给定的用户问题,对第4节的PaddleOCR识别的汽车说明书进行打分。
具体来讲,本节会将用户问题和PaddleOCR识别结果的文本进行拼接,生成测试集。然后默认会加载./Rerank/checkpoints/ranker模型,并基于该模型进行测试。最终测试结果将保存至./data/demo.score文件中。
%cd Rerank/
!bash run_test.sh 后备箱怎么开
%cd …
6. 跨模态阅读理解模块
本节首先获取排序模块输出的结果中评分最高的图片,然后将会使用跨模态的语言模型 LayoutXLM 从该图片中去抽取用户提问的答案。在获取答案后,将会对答案在该图片中进行高亮显示并返回用户。
LayoutXLM 专门用于处理多语言文档理解的跨模态预训练模型,如图5所示,其在建模过程中同时利用了视觉信息和文本信息,通过中两类模态信息增益文档理解,提高模型的文档理解能力。
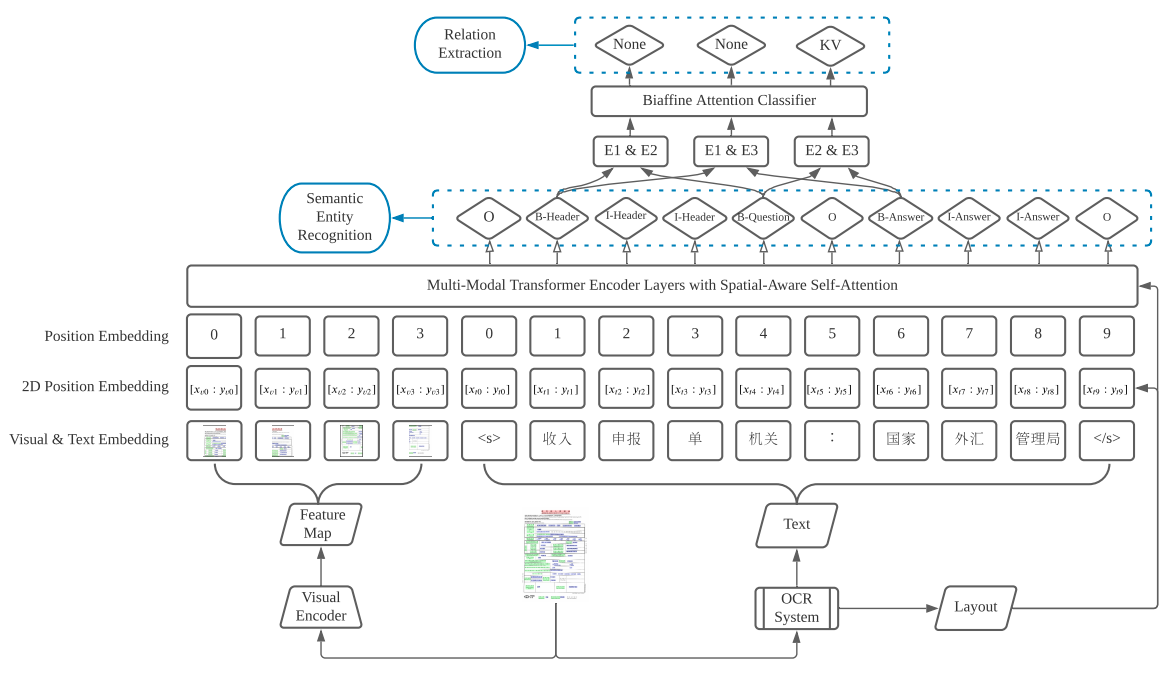
本模块将基于PaddleNLP, 使用文档解析模块生成的文本信息和布局信息(文本坐标信息)训练跨模态阅读理解语言模型。
6.1 模型训练
本项目提供了28条汽车说明书相关的训练样本,用于跨模态阅读理解模型的训练, 同时也提供了一个预先训练好的基线模型 base_model。 本模块可以使用 base_model 在汽车说明书训练样本上进一步微调,增强模型对汽车说明书领域的理解。
6.1.1 数据说明
跨模态阅读理解模型的训练集文件为./Extraction/data/train.json,其中重要的信息包括:“question”, “document”, “document_bbox"和"labels”, 如图6所示。
“question”: 用户提问的问题
“document”:文档解析模块识别出的文字(token)
“document_bbox”:每个token在汽车说明书上对应的坐标,分别对应(x_min, x_max, y_min, y_max)
“labels”: 阅读理解任务的标签数据

备注:汽车说明书的阅读理解模型训练集也可点击这里 手动下载,下载后将其重命名为 train.json ,存放至 ./Extraction/data/ 目录下便可。
6.1.2 模型训练
本节将基于 base_model 在汽车说明书的阅读理解数据集上进行微调训练。本节将基于LayoutXLM+CRF模型,通过序列标注的方式从给定的文档中,抽取问题的答案。
具体来讲,本节设定了4类标签:O, B-ans, I-ans 和 E-ans,用于从给定文档中抽取答案。即首先会将用户问题和文档进行拼接,然后传入LayoutXLM+CRF 模型进行阅读理解任务,模型会对输入文本序列预测相应的标签序列,然后便可以根据标签序列从给定文档中进行抽取答案了。
本节的base_model 是 Dureader retrieval 数据集训练的排序模型, 可使用如下命令下载:,下载完成后,将其解压至./Extraction/checkpoints 目录后,便可以获得该模型。
下载和解压代码实现如下:!mkdir -p ./Extraction/checkpoints
!wget https://paddlenlp.bj.bcebos.com/models/base_mrc.tar.gz
!tar -xzvf base_mrc.tar.gz -C ./Extraction/checkpoints/然后使用如下命令,便可以开始模型训练:%cd Extraction/
!bash run_train.sh
%cd …在训练过程中,会将模型存放至目录./Extraction/output下,训练结束后选择合适的模型移动至./checkpoints/ 目录下,并正式重命名为layoutxlm。
可以使用如下命令进行实现:%cd Extraction//
%mv output/checkpoint-280 checkpoints/
%mv checkpoints/checkpoint-280 checkpoints/layoutxlm
%cd …
6.2 模型测试
在模型训练完成后,便可以开启模型测试。本节将实现根据用户问题,从给定的汽车说明书中抽取问题答案。
具体来讲,本节会分析排序模块输出的打分结果,然后获取与用户问题最相关的汽车说明书,并将两者相关信息传入至 跨模态阅读理解 模型中,模型将会分析并给出预测结果。
接下来,可以根据预测结果中布局信息,对于该汽车说明书中的答案进行高亮显示,最终预测结果将保存至./answer.png文件中。
可以通过如下代码进行实现:
%cd Extraction
!bash run_test.sh 后备箱怎么开
%cd …其中,bash run_test.sh 后备箱怎么开 后面的参数为输入的用户问题。
7. 全流程预测
本项目汇总了以上流程,提供了全流程预测的功能,可通过如下命令进行一键式预测,只需要在执行命令的时候,输入想要咨询的问题,便可以启动全流程的预测功能。
!bash run_test.sh 后备箱怎么开预测答案将会保存至./answer.png文件中。
备注:在运行命令前,请确保已使用第4节介绍的命令对原始汽车说明书图片完成了文档解析。
图7 展示了用户提问的三个问题:“后备箱怎么开”,“钥匙怎么充电” 和 “NFC解锁注意事项”, 可以看到,本项目的汽车说明书问答系统能够精准地找到答案并进行高亮显示。
