1. 项目说明
图像语义分割在计算机视觉中是一个基本但具有挑战性的任务。它旨在提供详细的像素级图像分类,相当于为每个像素分配语义标签。该技术目前被广泛应用于城市安防、路况判断等系统领域。以我们选用的 KITTI-STEP 数据集为例,该项目的挑战在于:
1.目标复杂
道路复杂,包含直行,转弯,红绿灯路口等;
环境复杂,要适应白天、黑夜、雾天和雨天等;
场景复杂,城市道路、乡村、高速公路等场景差异性较大;
样本不均衡
类别多,包含:路面、人行道、建筑物、墙、栅栏、杆子、交通灯、交通标志、植被、地面、天空、人、骑车的人、车、卡车、巴士、火车、摩托车、自行车;
每张图像中最多达15辆车和30个行人,以及各种程度的遮挡与截断;
部分图像示例如下:



图 1 - KITTI-STEP 数据集示例
2. 安装说明
2.1 环境要求
paddlepaddle >= 2.0.0rc1
Python >= 3.6
强烈建议您安装/使用 GPU 版本的 PaddlePaddle。因为分割模型开销很大,当模型运行在 CPU 时可能会出现内存不足。更详细的安装教程请参考 PaddlePaddle 官网
2.2 解压数据及代码
项目代码在 paddleseg-kitti.tar 文件中,数据集在 kittistep.tar 文件中,解压到合适路径即可使用。# 如果希望解压到其他目录# 可选择其他路径(默认 /home/aistudio )
%cd ~
! unzip -qo ~/data/data141231/paddleseg-kitti.zip
! tar xf ~/data/data141231/kittistep.tar -C paddleseg-kitti/datasets
! mkdir paddleseg-kitti/pretrain &&
cp data/data141231/pretrain_cityscapes.pdparams paddleseg-kitti/pretrain
3. 数据准备
3.1 数据说明
KITTI-STEP 数据集源自 KITTI-MOTS 数据集,KITTI-MOTS 包含 training 21 个视频序列和 testing 29 个视频序列,KITTI-STEP 将训练集拆分出 12 个视频序列作为 training set,9 个视频序列作为 validation set,图像数量分别如下表所示
| 数据集 | train | val | test |
|---|---|---|---|
| 图像数量 | 5027 | 2981 | 11095 |
3.2 数据结构
文件的组织结构如下(参考 Run DeepLab2 on KITTI-STEP dataset
)
kittistep ├── images │ ├── train │ │ ├── 0000 │ │ │ ├── 000000.png │ │ │ ├── 000001.png │ │ │ ├── 000002.png │ │ │ ├── ... │ │ ├── 0001 │ │ ├── 0003 │ │ ├── ... │ └── val │ ├── 0007 │ ├── 0013 │ └── 0014 └── labels ├── train │ ├── 0000 │ ├── 0001 │ ├── 0003 │ ├── ... └── val ├── 0002 ├── 0006 ├── 0007 ├── ...
4. 模型选择
主流的语义分割方案包括如下几个系列:
FCN(Fully Convolution Network),顾名思义,即全卷积网络,做为使用深度学习做图像分割的先例,其象征意义更大于实际意义。FCN 的主要特点是整个网络全部是由卷积网络构成的,不包括全连接。
U-Net 系列:在 UNet 之前,主要的分割网络都是直筒式的,只使用顶层或后几层信息来上采样重建。而 UNet 是直接连接到输入端的卷积层。
DeepLab 系列:DeepLab 在图像分割领域中是另一个系列,目前已经有 DeepLab v1、DeepLab v2、DeepLab v3 和 DeepLab v3+ 等版本,和之前的 UNet 系列比起来,主要差别是在对输入图像的处理和网络的结构上。DeepLab 主要使用了图像金字塔、空洞卷积、SPP 空间金字塔池化、可分离卷积等方法来提高分割的效果。
HRNet 系列:HRNet 是 2019 年由微软亚洲研究院提出的一种全新的神经网络,不同于以往的卷积神经网络,该网络在网络深层仍然可以保持高分辨率,因此预测的语义信息更准确,在空间上也更精确。
Transformer 系列:自从 Transformer 被引入计算机视觉以来,催生了大量相关研究与应用。在图像分割方向,涌现了像 SETR、TransUNet、SegFormer、MaskFormer 等基于 Transformer 的语义分割网络模型。打破了卷积结构在图像全局信息访问限制的问题。
KITTI-STEP 数据与 Cityscapes 数据集类别及场景具有一定相似性,参考 Cityscapes val 的指标排行进行模型选型, 由于 MscaleOCRNet 模型的 mIoU 达到了 87% 的 SOTA 指标,因此基于该分割方法进行后续实验。MscaleOCRNet 从属于 HRNet 系列,相比于 HRNet 网络结构,它是在 HRNet 分割后的结果上计算每个像素与图像其他像素的一个关系权重,与原特征进行一个叠加构成 OCRNet 网络,再基于 OCRNet 进行分层多尺度训练形成最终的 MscaleOCRNet,多尺度训练与推理方式如下图所示。
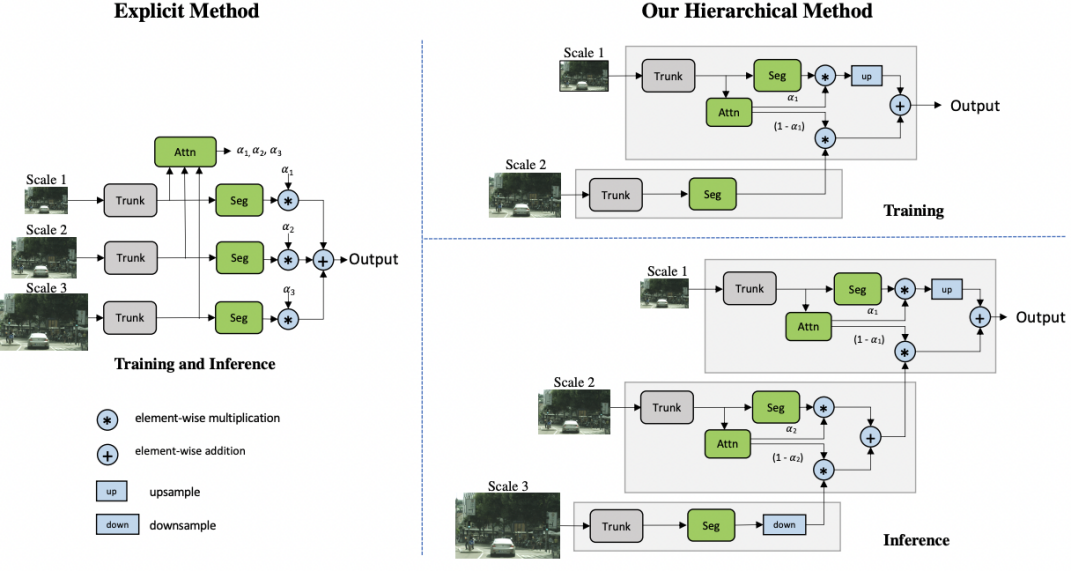
图 2 - MscaleOCRNet 方案
5. 模型训练
kitti 指标评估
| Model | Backbone | mIoU | Class IoU(包含背景类) |
|---|---|---|---|
| MscaleOCRNet | HRNet_w48 | 84.74% | [95.8 87.52 93.26 86.03 76.76 54.95 79.89 81.17 95.15 87.1 95.35 83.3 66.86 95.22 89.98 93.68 97.07 77.95 73.06] |
AI Studio 用户建议使用 GPU 进行训练。如果选择多卡 V100,需要将 CUDA_VISIBLE_DEVICES 改为卡数。
例如对于 4 卡 V100,需要将 CUDA_VISIBLE_DEVICES 设置为 CUDA_VISIBLE_DEVICES=0,1,2,3# 多卡训练
%cd ~/paddleseg-kitti
! export CUDA_VISIBLE_DEVICES=0 &&
python -u -m paddle.distributed.launch train.py
–config configs/mscale_ocr_kittistep.yml
–save_dir saved_model/mscale_ocr_kittistep
–save_interval 500
–num_workers 8
–do_eval
6. 模型评估
评估默认配置:configs/mscale_ocr_kittistep.yml。
具体配置可以到 yml 文件中查看,这里提供简单内容展示。
// 批大小 batch_size: 1 // 迭代次数 iters: 65000 model: type: MscaleOCRNet // 预训练模型路径 pretrained: pretrain/pretrain_cityscapes.pdparams n_scales: [1.0] // 主干网络 backbone: type: HRNet_W48_NV num_classes: 19 backbone_indices: [0] // 优化器配置 optimizer: type: sgd momentum: 0.9 weight_decay: 0.0001 // 学习率策略 lr_scheduler: type: PolynomialDecay learning_rate: 0.005 power: 2 end_lr: 0.0
「评估」时卡数选择同「训练」,需要将 CUDA_VISIBLE_DEVICES 修改为相应值。# 多卡评估
%cd ~/paddleseg-kitti
! CUDA_VISIBLE_DEVICES=0 &&
python -u -m paddle.distributed.launch predict.py
–config configs/mscale_ocr_kittistep.yml
–model_path saved_model/best_kittistep/model.pdparams
–image_path ./datasets/kittistep/images/train/0000
–aug_pred
–flip_horizontal
7. 模型优化
本小节侧重展示在模型迭代过程中优化精度的思路:
修改预训练模型:将 mapillary 预训练改为 Cityscapes 预训练模型,迁移至 KITTI-STEP 数据集训练可以有效提升分割效果;
增加多尺度训练:由 [0.5,1.0] 两个尺度增加至 [0.5,1.0,2.0] 三个尺度;
修改输入尺寸:修改输入尺寸由 1024x512 变为原图尺寸 1248x384;
| 预训练模型 | 多尺度训练 | 损失权重调整 | 指标 |
|---|---|---|---|
| 68.32% | |||
| ✔️ | 73.39% | ||
| ✔️ | ✔️ | 74.98% | |
| ✔️ | ✔️ | ✔️ | 77.57% |
8. 模型导出
导出推理模型
PaddlePaddle
框架保存的权重文件分为两种:支持前向推理和反向梯度的训练模型和只支持前向推理的推理模型。二者的区别是推理模型针对推理速度和显存做了优化,裁剪了一些只在训练过程中才需要的
tensor,降低显存占用,并进行了一些类似层融合,kernel 选择的速度优化。因此可执行如下命令导出推理模型。! bash
export.sh模型默认保存在 output/models 目录下。下图随机摘自 /output/result 目录,最终生成的图片都在该目录下。
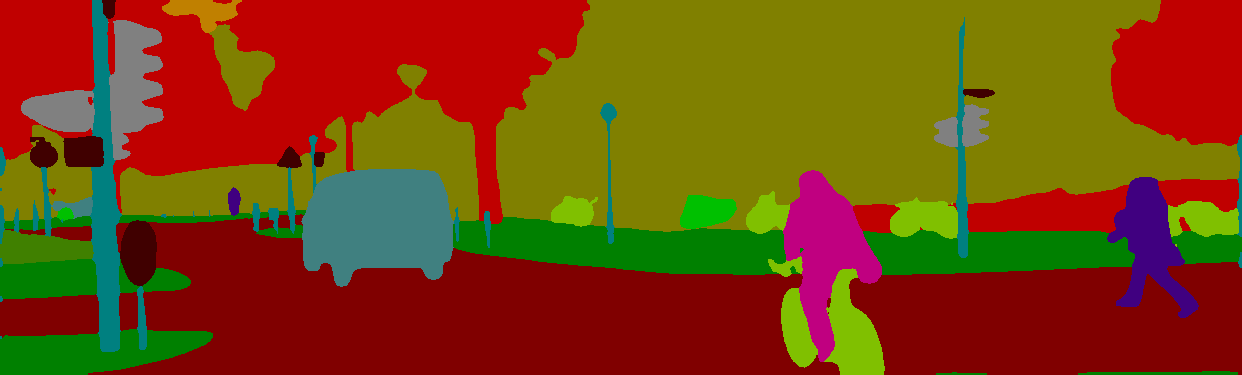

图 3 - 推理结果
9. 模型部署
使用飞桨原生推理库 paddle-inference,用于服务端模型部署
总体上分为三步:
创建 PaddlePredictor,设置所导出的模型路径
创建输入用的 PaddleTensor,传入到 PaddlePredictor 中
获取输出的 PaddleTensor ,将结果取出
#include "paddle_inference_api.h"
// 创建一个 config,并修改相关设置paddle::NativeConfig config;
config.model_dir = "xxx";
config.use_gpu = false;// 创建一个原生的 PaddlePredictorauto predictor =
paddle::CreatePaddlePredictor<paddle::NativeConfig>(config);// 创建输入 tensorint64_t data[4] = {1, 2, 3, 4};
paddle::PaddleTensor tensor;
tensor.shape = std::vector<int>({4, 1});
tensor.data.Reset(data, sizeof(data));
tensor.dtype = paddle::PaddleDType::INT64;// 创建输出 tensor,输出 tensor 的内存可以复用std::vector<paddle::PaddleTensor> outputs;// 执行预测CHECK(predictor->Run(slots, &outputs));// 获取 outputs ...更多内容详见 > C++ 预测 API介绍