1. 方案设计
车牌识别车牌识别就是使用OCR(Optical Character Recognition,光学字符识别)技术识别各类机动车车牌信息。目前,车牌识别已广泛应用在停车场、收费站、道路等交通设施中,提供高效便捷的车辆管理服务。OCR通常包含文本检测和文本识别两个子任务:
文字检测:检测图片中的文字位置;
文字识别:对文字区域中的文字进行识别。
使用OCR来识别车牌流程如 图1 所示,首先检测出车牌的位置(下图红色框区域)、然后对检测出来的车牌进行识别,即可得到右边的可编辑文本:

我们使用飞桨PaddleOCR实现车牌识别,接下来就一起来看看实现原理及具体实现步骤吧~
####如果您觉得本案例对您有帮助,欢迎Star收藏一下,不易走丢哦~,链接指路:https://github.com/PaddlePaddle/awesome-DeepLearning
2. 数据处理
2.1 数据集介绍
CCPD车牌数据集是采集人员在合肥停车场采集、手工标注得来,采集时间在早7:30到晚10:00之间。且拍摄车牌照片的环境复杂多变,包括雨天、雪天、倾斜、模糊等。CCPD数据集包含将近30万张图片、图片尺寸为720x1160x3,共包含8种类型图片,每种类型、数量及类型说明如下表:
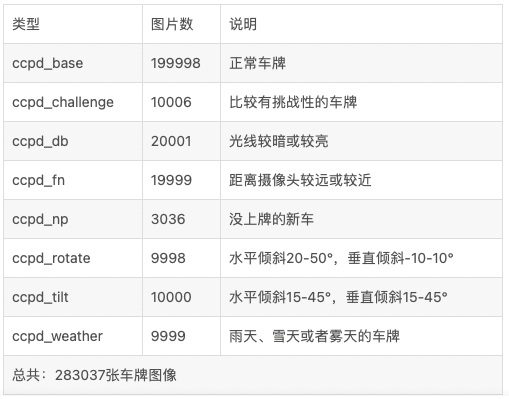
注:图2来源于开源车牌数据集CCPD介绍
CCPD数据集中每张图像的名称包含了标注信息,例如图片名称为"025-95_113-154&383_386&473-386&473_177&454_154&383_363&402-0_0_22_27_27_33_16-37-15.jpg",每个名称可以通过分隔符’-'分为几部分,每部分解释:
025:车牌区域占整个画面的比例;
95_113: 车牌水平和垂直角度, 水平95°, 竖直113°
154&383_386&473:标注框左上、右下坐标,左上(154, 383), 右下(386, 473)
386&473_177&454_154&383_363&402:标注框四个角点坐标,顺序为右下、左下、左上、右上
0_0_22_27_27_33_16:车牌号码映射关系如下: 第一个0为省份 对应省份字典provinces中的’皖’,;第二个0是该车所在地的地市一级代码,对应地市一级代码字典alphabets的’A’;后5位为字母和文字, 查看车牌号ads字典,如22为Y,27为3,33为9,16为S,最终车牌号码为
皖AY339S
provinces = ["皖", "沪", "津", "渝", "冀", "晋", "蒙", "辽", "吉", "黑", "苏", "浙", "京", "闽", "赣", "鲁", "豫", "鄂", "湘", "粤", "桂", "琼", "川", "贵", "云", "藏", "陕", "甘", "青", "宁", "新"] alphabets = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W','X', 'Y', 'Z'] ads = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X','Y', 'Z', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
本实验我们只使用正常车牌即ccpd_base的数据进行训练。
2.2 数据预处理
解压CCCP数据集:# 解压数据集
!mkdir dataset
!unzip -q data/data17968/CCPD2019.zip -d dataset/CCPD
%cd ~将CCPD的数据格式转换PaddleOCR检测所需格式,执行下面代码即可:import os
import os.path as osp
import cv2
ads = [‘A’, ‘B’, ‘C’, ‘D’, ‘E’, ‘F’, ‘G’, ‘H’, ‘J’, ‘K’, ‘L’, ‘M’,
‘N’, ‘P’, ‘Q’, ‘R’, ‘S’, ‘T’, ‘U’, ‘V’, ‘W’, ‘X’,‘Y’, ‘Z’,
‘0’, ‘1’, ‘2’, ‘3’, ‘4’, ‘5’, ‘6’, ‘7’, ‘8’, ‘9’]
provinces = [“皖”, “沪”, “津”, “渝”, “冀”, “晋”, “蒙”, “辽”, “吉”, “黑”, “苏”,
“浙”, “京”, “闽”, “赣”, “鲁”, “豫”, “鄂”, “湘”, “粤”, “桂”, “琼”,
“川”, “贵”, “云”, “藏”, “陕”, “甘”, “青”, “宁”, “新”]
#转换检测数据
train_det = open(‘dataset/train_det.txt’, ‘w’, encoding=‘UTF-8’)
dev_det = open(‘dataset/dev_det.txt’, ‘w’, encoding=‘UTF-8’)
#转换识别数据
if not osp.exists(‘dataset/img’):
os.mkdir(‘dataset/img’)
train_rec = open(‘dataset/train_rec.txt’, ‘w’, encoding=‘UTF-8’)
dev_rec = open(‘dataset/dev_rec.txt’, ‘w’, encoding=‘UTF-8’)
count = 0
#总样本数
total_num = len(os.listdir(‘dataset/CCPD/ccpd_base’))
#训练样本数
train_num = int(total_num*0.8)
for item in os.listdir(‘dataset/CCPD/ccpd_base’):
path = ‘dataset/CCPD/ccpd_base/’+item
_, _, bboxs, points, labels, , _ = item.split(’-’)
bboxs = bboxs.split(’’)
x1, y1 = bboxs[0].split(’&’)
x2, y2 = bboxs[1].split(’&’)
bboxs = [int(coord) for coord in [x1, y1, x2, y2]]
points = points.split('_')
points = [point.split('&') for point in points]
points_ = points[-2:]+points[:2]
points = []
for point in points_:
points.append([int(_) for _ in point])
labels = labels.split('_')
prov = provinces[int(labels[0])]
plate_number = [ads[int(label)] for label in labels[1:]]
labels = prov+''.join(plate_number)
#获取检测训练检测框位置
line_det = path+'\t'+'[{"transcription": "%s", "points": %s}]' % (labels, str(points))
line_det = line_det[:]+'\n'
#获取识别训练图片及标签
img = cv2.imread(path)
crop = img[bboxs[1]:bboxs[3], bboxs[0]:bboxs[2], :]
cv2.imwrite('dataset/img/%06d.jpg' % count, crop)
line_rec = 'dataset/img/%06d.jpg\t%s\n' % (count, labels)
# 写入txt
if count <= train_num:
train_det.write(line_det)
train_rec.write(line_rec)
else:
val_det.write(line_det)
dev_rec.write(line_rec)
count += 1train_det.close()
dev_det.close()
train_rec.close()
dev_det.close()
#创建字典文件
with open(‘dataset/dict.txt’, ‘w’, encoding=‘UTF-8’) as file:
for key in ads+provinces:
file.write(key+’\n’)
3. 模型介绍
3.1 PaddleOCR算法列表
PaddleOCR中提供了如下文本检测算法和文本识别算法列表,以及每个算法在英文公开数据集上的模型和指标,主要用于算法简介和算法性能对比。
文本检测算法:
| 模型 | 骨干网络 | precision | recall | Hmean | 下载链接 |
|---|---|---|---|---|---|
| EAST | ResNet50_vd | 85.80% | 86.71% | 86.25% | 预训练模型 |
| EAST | MobileNetV3 | 79.42% | 80.64% | 80.03% | 预训练模型 |
| DB | ResNet50_vd | 86.41% | 78.72% | 82.38% | 预训练模型 |
| DB | MobileNetV3 | 77.29% | 73.08% | 75.12% | 预训练模型 |
| SAST | ResNet50_vd | 91.39% | 83.77% | 87.42% | 预训练模型 |
文本识别算法:
| 模型 | 骨干网络 | Avg Accuracy | 模型存储命名 | 下载链接 |
|---|---|---|---|---|
| Rosetta | Resnet34_vd | 80.9% | rec_r34_vd_none_none_ctc | 预训练模型 |
| Rosetta | MobileNetV3 | 78.05% | rec_mv3_none_none_ctc | 预训练模型 |
| CRNN | Resnet34_vd | 82.76% | rec_r34_vd_none_bilstm_ctc | 预训练模型 |
| CRNN | MobileNetV3 | 79.97% | rec_mv3_none_bilstm_ctc | 预训练模型 |
| StarNet | Resnet34_vd | 84.44% | rec_r34_vd_tps_bilstm_ctc | 预训练模型 |
| StarNet | MobileNetV3 | 81.42% | rec_mv3_tps_bilstm_ctc | 预训练模型 |
| RARE | MobileNetV3 | 82.5% | rec_mv3_tps_bilstm_att | 预训练模型 |
| RARE | Resnet34_vd | 83.6% | rec_r34_vd_tps_bilstm_att | 预训练模型 |
| SRN | Resnet50_vd_fpn | 88.52% | rec_r50fpn_vd_none_srn | 预训练模型 |
| NRTR | NRTR_MTB | 84.3% | rec_mtb_nrtr | 预训练模型 |
考虑车牌识别中字符数量较少,而且长度也固定,且为标准的印刷字体,所以无需使用过于复杂的模型。我们选择DBNet检测算法和CRNN识别模型作,PaddleOCR的检测模型目前支持两种backbone,分别是MobileNetV3、ResNet_vd系列,本实验两个模型均使用MobileNetV3作为其主干网络(Backbone)。
3.2 安装PaddleOCR
本项目中已经帮大家安装好了最新版的PaddleOCR,且修改好配置文件,无需安装~
如仍需安装or安装更新,可以执行以下步骤(目前支持Clone GitHub【推荐】和Gitee两种方式):
注:码云托管代码可能无法实时同步本github项目更新,存在3~5天延时,请优先使用推荐方式。!git clone https://github.com/PaddlePaddle/PaddleOCR
#如果因为网络问题无法pull成功,也可选择使用码云上的托管:
#!git clone https://gitee.com/paddlepaddle/PaddleOCR
#安装依赖
%cd PaddleOCR
!pip install -r requirements.txt
%cd …
3.3 下载预训练模型
首先下载模型backbone的pretrain model,您可以根据需求使用PaddleClas中的模型更换backbone,
对应的backbone预训练模型可以从PaddleClas repo 主页中找到下载链接。%cd PaddleOCR/
#下载MobileNetV3的检测预训练模型
!wget -P ./pretrain_models/ https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/MobileNetV3_large_x0_5_pretrained.pdparams
%cd …# 下载MobileNetV3的识别预训练模型
%cd PaddleOCR/
!wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/rec_mv3_none_bilstm_ctc_v2.0_train.tar
#解压模型参数
!tar -xvf pretrain_models/rec_mv3_none_bilstm_ctc_v2.0_train.tar -C pretrain_models/
!rm -rf pretrain_models/rec_mv3_none_bilstm_ctc_v2.0_train.tar
%cd …
4 模型训练
4.1 训练检测模型
首先我们需要修改configs/det/det_mv3_db.yml文件中Train和eval数据集的图片路径data_dir和标签路径label_file_list。
如果您安装的是paddle cpu版本,需要将det_mv3_db.yml配置文件中的use_gpu字段修改为false%cd PaddleOCR/# 单机单卡训练 mv3_db 模型
!python tools/train.py -c configs/det/det_mv3_db.yml
-o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
#单机多卡训练,通过 --gpus 参数设置使用的GPU ID
#!python -m paddle.distributed.launch --gpus ‘0,1,2,3’ tools/train.py -c configs/det/det_mv3_db.yml
#-o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained上述指令中,通过-c 选择训练使用configs/det/det_db_mv3.yml配置文件。 有关配置文件的详细解释,请参考链接。
您也可以通过-o参数在不需要修改yml文件的情况下,改变训练的参数,比如,调整训练的学习率为0.0001
`!python tools/train.py -c configs/det/det_mv3_db.yml -o Optimizer.base_lr=0.0001
4.2 训练识别模型
如果您是在自己的数据集上训练的模型,并且调整了中文字符的字典文件,请注意修改配置文件configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml中的character_dict_path是否是所需要的字典文件。同时修改Train和eval的图片路径data_dir和标签路径label_file_list。
同检测模型,如果您安装的是cpu版本,请将配置文件中的 use_gpu 字段修改为false# GPU训练 支持单卡,多卡训练
#单卡训练(训练周期长,不建议)
!python tools/train.py -c configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml
#多卡训练,通过–gpus参数指定卡号
#!python -m paddle.distributed.launch --gpus ‘0,1,2,3’ tools/train.py
-c
configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.ymlPaddleOCR支持训练和评估交替进行,
可以在rec_chinese_lite_train_v2.0.yml中修改 eval_batch_step
设置评估频率,默认每500个iter评估一次。评估过程中默认将最佳acc模型,保存为
output/rec_CRNN/best_accuracy。如果验证集很大,测试将会比较耗时,建议减少评估次数,或训练完再进行评估。
5 模型导出
将训练好的模型转换成inference模型只需要运行如下命令:# 导出检测模型
!python tools/export_model.py
-c configs/det/det_mv3_db.yml
-o Global.pretrained_model=./output/db_mv3/best_accuracy
Global.save_inference_dir=./inference/db_mv3/# 导出识别模型
!python tools/export_model.py
-c configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml
-o Global.checkpoints=./output/rec_chinese_lite_v2.0/best_accuracy
Global.save_inference_dir=./inference/rec_chinese_lite_v2.0/其中:
-c 后面设置训练算法的yml配置文件
-o 配置可选参数
Global.pretrained_model 参数设置待转换的训练模型地址,不用添加文件后缀 .pdmodel,.pdopt或.pdparams。
Global.save_inference_dir参数设置转换的模型将保存的地址。
转inference模型时,使用的配置文件和训练时使用的配置文件相同。另外,还需要设置配置文件中的Global.pretrained_model参数,其指向训练中保存的模型参数文件。 转换成功后,在模型保存目录下有三个文件:
/inference/*/ ├── inference.pdiparams # inference模型的参数文件 ├── inference.pdiparams.info # inference模型的参数信息,可忽略 └── inference.pdmodel # inference模型的program文件
6. 模型推理
在执行预测时,需要通过参数image_dir指定单张图像或者图像集合的路径、参数det_model_dir,cls_model_dir和rec_model_dir分别指定检测,方向分类和识别的inference模型路径。参数use_angle_cls用于控制是否启用方向分类模型。如果训练时修改了文本的字典,在使用inference模型预测时,需要通过–rec_char_dict_path指定使用的字典路径,并且设置
rec_char_type=ch。可视化识别结果默认保存到 ./inference_results 文件夹里面。!python3
tools/infer/predict_system.py
–image_dir="./doc/imgs/00018069.jpg"
–det_model_dir="./inference/db_mv3/"
–rec_model_dir="./inference/rec_chinese_lite_v2.0/"
–rec_char_dict_path="…/dict.txt"
–rec_char_type=ch
–use_angle_cls=false
–output=…/output/table
–vis_font_path=./doc/fonts/simfang.ttf
资源
更多资源请参考:
更多深度学习知识、产业案例,请参考:awesome-DeepLearning
更多PaddleOCR使用教程,请参考:PaddleOCR
飞桨框架相关资料,请参考:飞桨深度学习平台
参考文献
1. CCPD:
@inproceedings{xu2018towards,
title={Towards End-to-End License Plate Detection and Recognition: A Large Dataset and baseline},
author={Xu, Zhenbo and Yang, Wei and Meng, Ajin and Lu, Nanxue and Huang, Huan},
booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
pages={255--271},
year={2018}
}
2. DB:
@inproceedings{liao2020real,
title={Real-Time Scene Text Detection with Differentiable Binarization.},
author={Liao, Minghui and Wan, Zhaoyi and Yao, Cong and Chen, Kai and Bai, Xiang},
booktitle={AAAI},
pages={11474--11481},
year={2020}
}
3. CRNN:
@article{shi2016end,
title={An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition},
author={Shi, Baoguang and Bai, Xiang and Yao, Cong},
journal={IEEE transactions on pattern analysis and machine intelligence},
volume={39},
number={11},
pages={2298--2304},
year={2016},
publisher={IEEE}
}参考项目
此项目参考【寂寞你快进去】的"PaddleOCR:车牌识别"项目,原项目地址为:https://aistudio.baidu.com/aistudio/projectdetail/739559?channelType=0&channel=0