机器阅读理解是自然语言处理中的一个重要的任务,最常见的有单篇章的抽取式阅读理解。机器阅读理解的应用范围很广,比如客服机器人,通过文字或者语音与用户进行沟通交流,然后获取相关的信息并提供准确可靠的回答。搜索引擎中精确返回用户所给定问题的答案。在医疗领域中自动阅读病人的资料来找到相应的病因。在教育领域中,利用阅读理解模型自动为学生的作文给出改进意见等等。
学习资源
更多的深度学习资料,比如深度学习知识,论文解读,实践案例等,请参考:awesome-DeepLearning
更多飞桨框架相关资料,请参考:飞桨深度学习平台
⭐ ⭐ ⭐ 欢迎点个小小的Star,开源不易,希望大家多多支持~⭐ ⭐ ⭐

一、方案设计
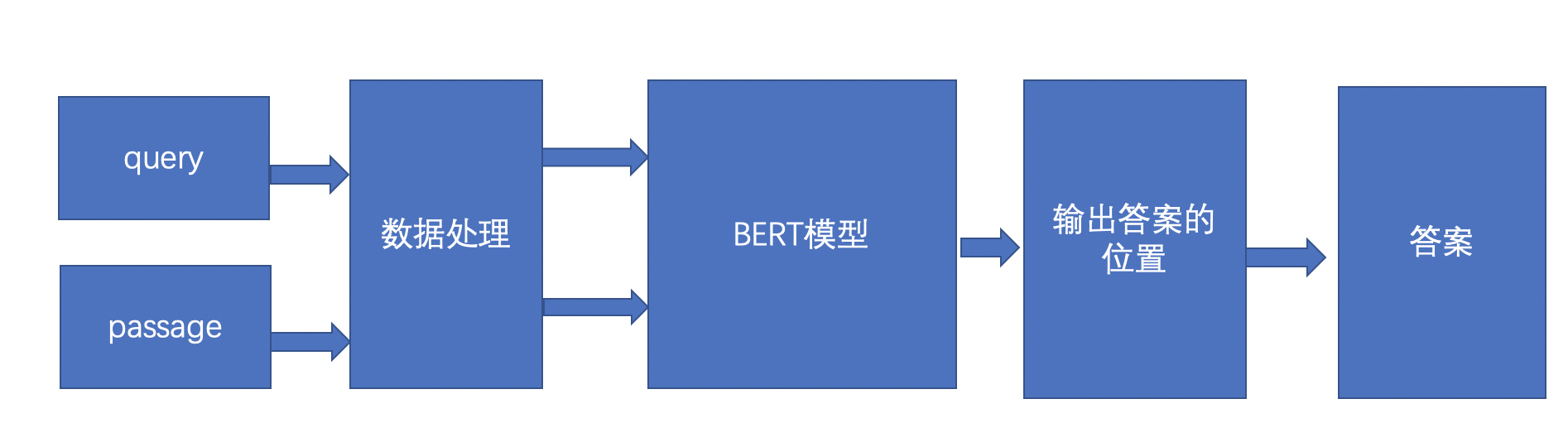
阅读理解的方案如上图,首先是query表示的是问句,一般是用户的提问,passage表示的是文章,表示的是query的答案要从passage里面抽取出来,query和passage经过数据预处理,得到id形式的输入,然后把query,passage的id形式输入到BERT模型里面,BERT模型经过处理会输出答案的位置,输出位置以后就可以得到相应的答案了。
二、 数据处理
具体的任务定义为:对于一个给定的问题q和一个篇章p,根据篇章内容,给出该问题的答案a。数据集中的每个样本,是一个三元组<q, p, a>,例如:
问题 q: 乔丹打了多少个赛季
篇章 p: 迈克尔.乔丹在NBA打了15个赛季。他在84年进入nba,期间在1993年10月6日第一次退役改打棒球,95年3月18日重新回归,在99年1月13日第二次退役,后于2001年10月31日复出,在03年最终退役…
参考答案 a: [‘15个’,‘15个赛季’]
阅读理解模型的鲁棒性是衡量该技术能否在实际应用中大规模落地的重要指标之一。随着当前技术的进步,模型虽然能够在一些阅读理解测试集上取得较好的性能,但在实际应用中,这些模型所表现出的鲁棒性仍然难以令人满意。本示例使用的DuReader-robust数据集作为首个关注阅读理解模型鲁棒性的中文数据集,旨在考察模型在真实应用场景中的过敏感性、过稳定性以及泛化能力等问题。
关于该数据集的详细内容,可参考数据集论文,或官方比赛链接。首先导入实验所需要用到的库包。from paddlenlp.datasets import load_dataset
import paddlenlp as ppnlp
from utils import prepare_train_features, prepare_validation_features
from functools import partial
from paddlenlp.metrics.squad import squad_evaluate, compute_prediction
import collections
import time
import json
2.1 数据集加载
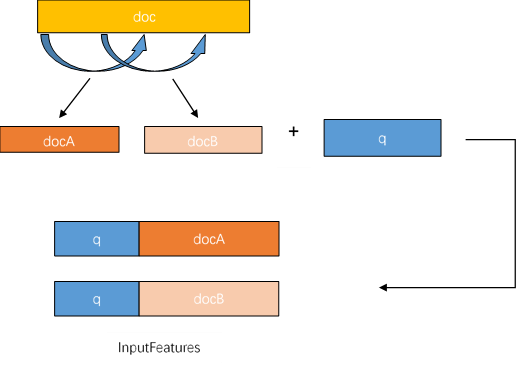
PaddleNLP已经内置SQuAD,CMRC等中英文阅读理解数据集,使用paddlenlp.datasets.load_dataset()API即可一键加载。本实例加载的是DuReaderRobust中文阅读理解数据集。由于DuReaderRobust数据集采用SQuAD数据格式,InputFeature使用滑动窗口的方法生成,即一个example可能对应多个InputFeature。
答案抽取任务即根据输入的问题和文章,预测答案在文章中的起始位置和结束位置。
由于文章加问题的文本长度可能大于max_seq_length,答案出现的位置有可能出现在文章最后,所以不能简单��对文章进行截断。
那么对于过长的文章,则采用滑动窗口将文章分成多段,分别与问题组合。再用对应的tokenizer转化为模型可接受的feature。doc_stride参数就是每次滑动的距离。滑动窗口生成InputFeature的过程如下图:
train_ds, dev_ds = ppnlp.datasets.load_dataset(‘dureader_robust’, splits=(‘train’, ‘dev’))
for idx in range(2):
print(train_ds[idx][‘question’])
print(train_ds[idx][‘context’])
print(train_ds[idx][‘answers’])
print(train_ds[idx][‘answer_starts’])
print()ppnlp.transformers.BertTokenizer
调用BertTokenizer进行数据处理。
预训练模型Bert对中文数据的处理是以字为单位。PaddleNLP对于各种预训练模型已经内置了相应的tokenizer,指定想要使用的��型名字即可加载对应的tokenizer。
tokenizer的作用是将原始输入文本转化成模型可以接受的输入数据形式。MODEL_NAME = “bert-base-chinese”
tokenizer = ppnlp.transformers.BertTokenizer.from_pretrained(MODEL_NAME)
2.2 数据处理
使用load_dataset()API默认读取到的数据集是MapDataset对象,MapDataset是paddle.io.Dataset的功能增强版本。其内置的map()方法适合用来进行批量数据集处理。map()方法传入的是一个用于数据处理的function。
以下是Dureader-Robust中数据转化的用法:max_seq_length = 512
doc_stride = 128
train_trans_func = partial(prepare_train_features,
max_seq_length=max_seq_length,
doc_stride=doc_stride,
tokenizer=tokenizer)
train_ds.map(train_trans_func, batched=True)
dev_trans_func = partial(prepare_validation_features,
max_seq_length=max_seq_length,
doc_stride=doc_stride,
tokenizer=tokenizer)
dev_ds.map(dev_trans_func, batched=True)for idx in range(2):
print(train_ds[idx][‘input_ids’])
print(train_ds[idx][‘token_type_ids’])
print(train_ds[idx][‘overflow_to_sample’])
print(train_ds[idx][‘offset_mapping’])
print(train_ds[idx][‘start_positions’])
print(train_ds[idx][‘end_positions’])
print()从以上结果可以看出,数据集中的example已经被转换成了模型可以接收的feature,包括input_ids、token_type_ids、答案的起始位置等信息。
其中:
input_ids: 表示输入文本的token ID。token_type_ids: 表示对应的token属于输入的问题还是答案。(Transformer类预训练模型支持单句以及句对输入)。overflow_to_sample: feature对应的example的编号。offset_mapping: 每个token的起始字符和结束字符在原文中对应的index(用于生成答案文本)。start_positions: 答案在���个feature中的开始位置。end_positions: 答案在这个feature中的结束位置。
2.3 构造Dataloader
使用paddle.io.DataLoader接口多线程异步加载数据。同时使用paddlenlp.data中提供的方法把feature组成batchimport paddle
from paddlenlp.data import Stack, Dict, Pad
batch_size = 8
train_batch_sampler = paddle.io.DistributedBatchSampler(
train_ds, batch_size=batch_size, shuffle=True)
train_batchify_fn = lambda samples, fn=Dict({
“input_ids”: Pad(axis=0, pad_val=tokenizer.pad_token_id),
“token_type_ids”: Pad(axis=0, pad_val=tokenizer.pad_token_type_id),
“start_positions”: Stack(dtype=“int64”),
“end_positions”: Stack(dtype=“int64”)
}): fn(samples)
train_data_loader = paddle.io.DataLoader(
dataset=train_ds,
batch_sampler=train_batch_sampler,
collate_fn=train_batchify_fn,
return_list=True)
dev_batch_sampler = paddle.io.BatchSampler(
dev_ds, batch_size=batch_size, shuffle=False)
dev_batchify_fn = lambda samples, fn=Dict({
“input_ids”: Pad(axis=0, pad_val=tokenizer.pad_token_id),
“token_type_ids”: Pad(axis=0, pad_val=tokenizer.pad_token_type_id)
}): fn(samples)
dev_data_loader = paddle.io.DataLoader(
dataset=dev_ds,
batch_sampler=dev_batch_sampler,
collate_fn=dev_batchify_fn,
return_list=True)
三、模型构建
阅读理解本质是一个答案抽取任务,PaddleNLP对于各种预训练模型已经内置了对于下游任务-答案抽取的Fine-tune网络。
以下项目以BERT为例,介绍如何将预训练模型Fine-tune完成答案抽取任务。
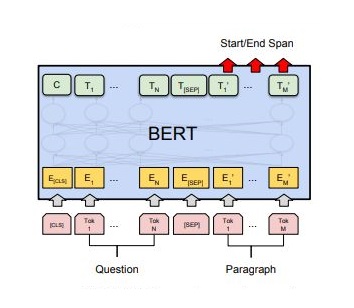
答案抽取任务的本质就是根据输入的问题和文章,预测答案在文章中的起始位置和结束位置。基于BERT的答案抽取原理如下图所示:
paddlenlp.transformers.BertForQuestionAnswering()
一行代码即可加载预训练模型BERT用于答案抽取任务的Fine-tune网络。
paddlenlp.transformers.BertForQuestionAnswering.from_pretrained()
指定想要使用的模型名称和文本分类的类别数,一行代码完成网络构建。# 设置想要使用模型的名称
model = ppnlp.transformers.BertForQuestionAnswering.from_pretrained(MODEL_NAME)
四、模型配置
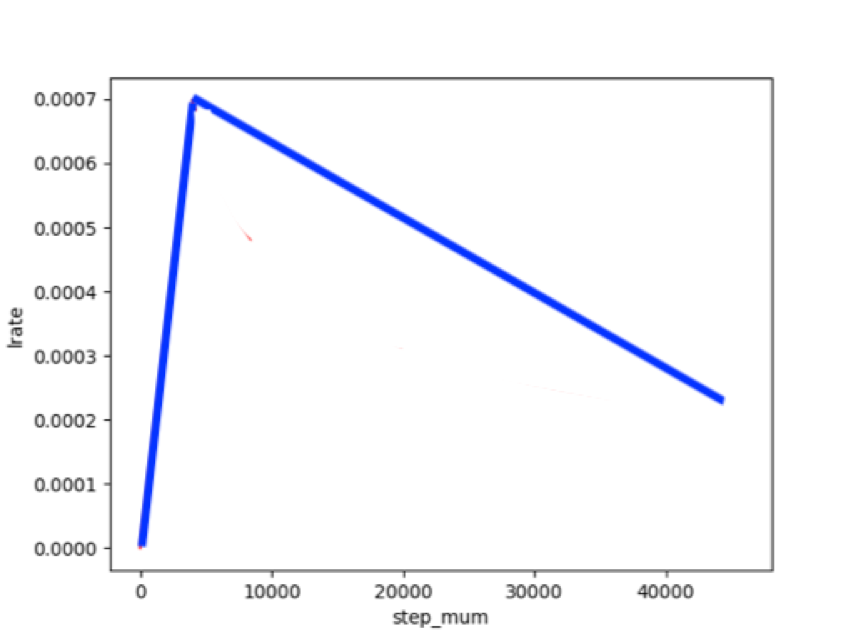
4.1 设置Fine-Tune优化策略
适用于ERNIE/BERT这类Transformer模型的学习率为warmup的动态学习率。
#训练过程中的最大学习率
learning_rate = 3e-5
#训练轮次
epochs = 1
#学习率预热比例
warmup_proportion = 0.1
#权重衰减系数,类似模型正则项策略,避免模型过拟合
weight_decay = 0.01
num_training_steps = len(train_data_loader) * epochs
lr_scheduler = ppnlp.transformers.LinearDecayWithWarmup(learning_rate, num_training_steps, warmup_proportion)
#Generate parameter names needed to perform weight decay.
#All bias and LayerNorm parameters are excluded.
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in [“bias”, “norm”])
]
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in decay_params)
4.2 设计loss function
由于BertForQuestionAnswering模型对将BertModel的sequence_output拆开成start_logits和end_logits进行输出,所以阅读理解任务的loss也由start_loss和end_loss组成,我们需要自己定义loss
function。对于答案其实位置和结束位置的预测可以分别成两个分类任务。所以设计的loss function如下:class
CrossEntropyLossForSQuAD(paddle.nn.Layer):
def init(self):
super(CrossEntropyLossForSQuAD, self).init()
def forward(self, y, label): start_logits, end_logits = y # both shape are [batch_size, seq_len] start_position, end_position = label start_position = paddle.unsqueeze(start_position, axis=-1) end_position = paddle.unsqueeze(end_position, axis=-1) start_loss = paddle.nn.functional.softmax_with_cross_entropy( logits=start_logits, label=start_position, soft_label=False) start_loss = paddle.mean(start_loss) end_loss = paddle.nn.functional.softmax_with_cross_entropy( logits=end_logits, label=end_position, soft_label=False) end_loss = paddle.mean(end_loss) loss = (start_loss + end_loss) / 2 return loss
五、模型训练
模型训练的过程通常有以下步骤:
从dataloader中取出一个batch data
将batch data喂给model,做前向计算
将前向计算结果传给损失函数,计算loss��
loss反向回传,更新梯度。重复以上步骤。
每训练一个epoch时,程序通过evaluate()调用paddlenlp.metric.squad中的squad_evaluate(), compute_predictions()评估当前模型训练的效果,其中:
compute_predictions()用于生成可提交的答案;
squad_evaluate()用于返回评价指标。
二者适用于所有符合squad数据格式的答案抽取任务。这类任务使用Rouge-L和exact来评估预测的答案和真实答案的相似程度。@paddle.no_grad()
def evaluate(model, data_loader):
model.eval()
all_start_logits = []
all_end_logits = []
tic_eval = time.time()
for batch in data_loader:
input_ids, token_type_ids = batch
start_logits_tensor, end_logits_tensor = model(input_ids,
token_type_ids)
for idx in range(start_logits_tensor.shape[0]):
if len(all_start_logits) % 1000 == 0 and len(all_start_logits):
print("Processing example: %d" % len(all_start_logits))
print('time per 1000:', time.time() - tic_eval)
tic_eval = time.time()
all_start_logits.append(start_logits_tensor.numpy()[idx])
all_end_logits.append(end_logits_tensor.numpy()[idx])
all_predictions, _, _ = compute_prediction(
data_loader.dataset.data, data_loader.dataset.new_data,
(all_start_logits, all_end_logits), False, 20, 30)
squad_evaluate(
examples=data_loader.dataset.data,
preds=all_predictions,
is_whitespace_splited=False)
model.train()# from utils import evaluatecriterion = CrossEntropyLossForSQuAD()
global_step = 0
for epoch in range(1, epochs + 1):
for step, batch in enumerate(train_data_loader, start=1):
global_step += 1
input_ids, segment_ids, start_positions, end_positions = batch
logits = model(input_ids=input_ids, token_type_ids=segment_ids)
loss = criterion(logits, (start_positions, end_positions))
if global_step % 100 == 0 :
print("global step %d, epoch: %d, batch: %d, loss: %.5f" % (global_step, epoch, step, loss))
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad()
evaluate(model=model, data_loader=dev_data_loader)model.save_pretrained(’./checkpoint’)
tokenizer.save_pretrained(’./checkpoint’)更多预训练模型
PaddleNLP不仅支持BERT预训练模型,还支持ERNIE、RoBERTa、Electra等预训练模型。
下表汇总了目前PaddleNLP支持的各类预训练模型。用户可以使用PaddleNLP提供的模型,完成问答、序列分类、token分类等任务。同时我们提供了22种预训练的参数权重供用户使用,其中包含了11种中文语言模型的预训练权重。
| Model | Tokenizer | Supported Task | Model Name |
|---|---|---|---|
| BERT | BertTokenizer | BertModel BertForQuestionAnswering BertForSequenceClassification BertForTokenClassification | bert-base-uncasedbert-large-uncased bert-base-multilingual-uncased bert-base-casedbert-base-chinesebert-base-multilingual-casedbert-large-casedbert-wwm-chinesebert-wwm-ext-chinese |
| ERNIE | ErnieTokenizer ErnieTinyTokenizer | ErnieModel ErnieForQuestionAnswering ErnieForSequenceClassification ErnieForTokenClassification | ernie-1.0ernie-tinyernie-2.0-enernie-2.0-large-en |
| RoBERTa | RobertaTokenizer | RobertaModel RobertaForQuestionAnswering RobertaForSequenceClassification RobertaForTokenClassification | roberta-wwm-extroberta-wwm-ext-largerbt3rbtl3 |
| ELECTRA | ElectraTokenizer | ElectraModel ElectraForSequenceClassification ElectraForTokenClassification | electra-smallelectra-baseelectra-largechinese-electra-smallchinese-electra-base |
注:其中中文的预训练模型有 bert-base-chinese, bert-wwm-chinese,
bert-wwm-ext-chinese, ernie-1.0, ernie-tiny, roberta-wwm-ext,
roberta-wwm-ext-large, rbt3, rbtl3, chinese-electra-base,
chinese-electra-small 等。
更多预训练模型参考:https://github.com/PaddlePaddle/models/blob/develop/PaddleNLP/docs/transformers.md
更多预训练模型fine-tune下游任务使用方法,请参考examples。
六、模型预测
@paddle.no_grad()
def do_predict(model, data_loader):
model.eval()
all_start_logits = []
all_end_logits = []
tic_eval = time.time()
for batch in data_loader:
input_ids, token_type_ids = batch
start_logits_tensor, end_logits_tensor = model(input_ids,
token_type_ids)
for idx in range(start_logits_tensor.shape[0]):
if len(all_start_logits) % 1000 == 0 and len(all_start_logits):
print("Processing example: %d" % len(all_start_logits))
print('time per 1000:', time.time() - tic_eval)
tic_eval = time.time()
all_start_logits.append(start_logits_tensor.numpy()[idx])
all_end_logits.append(end_logits_tensor.numpy()[idx])
all_predictions, _, _ = compute_prediction(
data_loader.dataset.data, data_loader.dataset.new_data,
(all_start_logits, all_end_logits), False, 20, 30)
count = 0
for example in data_loader.dataset.data:
count += 1
print()
print('问题:',example['question'])
print('原文:',''.join(example['context']))
print('答案:',all_predictions[example['id']])
if count >= 2:
break
model.train()do_predict(model, dev_data_loader)
七. 更多深度学习资源
7.1 一站式深度学习平台[awesome-DeepLearning]
(https://github.com/paddlepaddle/awesome-DeepLearning)
深度学习入门课
深度学习百问

特色课

产业实践
PaddleEdu使用过程中有任何问题欢迎在awesome-DeepLearning提issue,同时更多深度学习资料请参阅飞桨深度学习平台。
记得点个Star⭐收藏噢~~

本案例数据集来源于:https://aistudio.baidu.com/aistudio/competition/detail/49/0/task-definition