意图识别是指分析用户的核心需求,输出与查询输入最相关的信息,例如在搜索中要找电影、查快递、市政办公等需求,这些需求在底层的检索策略会有很大的不同,错误的识别几乎可以确定找不到能满足用户需求的内容,导致产生非常差的用户体验;在对话过程中要准确理解对方所想表达的意思,这是具有很大挑战性的任务。
例如用户输入查询“仙剑奇侠传”时,我们知道“仙剑奇侠传”既有游戏又有电视剧还有新闻、图片等等,如果我们通过用户意图识别发现该用户是想看“仙剑奇侠传”电视剧的,那我们直接把电视剧作为结果返回给用户,就会节省用户的搜索点击次数,缩短搜索时间,大大提升使用体验。而在对话中如果对方说“我的苹果从不出现卡顿”,那么我们就能通过意图识别判断出此刻的苹果是一个电子设备,而非水果,这样对话就能顺利进行下去。
本示例使用ERNIE预训练模型,在CrossWOZ数据集上完成任务型对话中的槽位填充和意图识别任务,这两个任务是一个pipeline型任务对话系统的基石。
学习资源
更多的深度学习资料,比如深度学习知识,论文解读,实践案例等,请参考:awesome-DeepLearning
更多飞桨框架相关资料,请参考:飞桨深度学习平台
⭐ ⭐ ⭐ 欢迎点个小小的Star,开源不易,希望大家多多支持~⭐ ⭐ ⭐

1. 方案设计
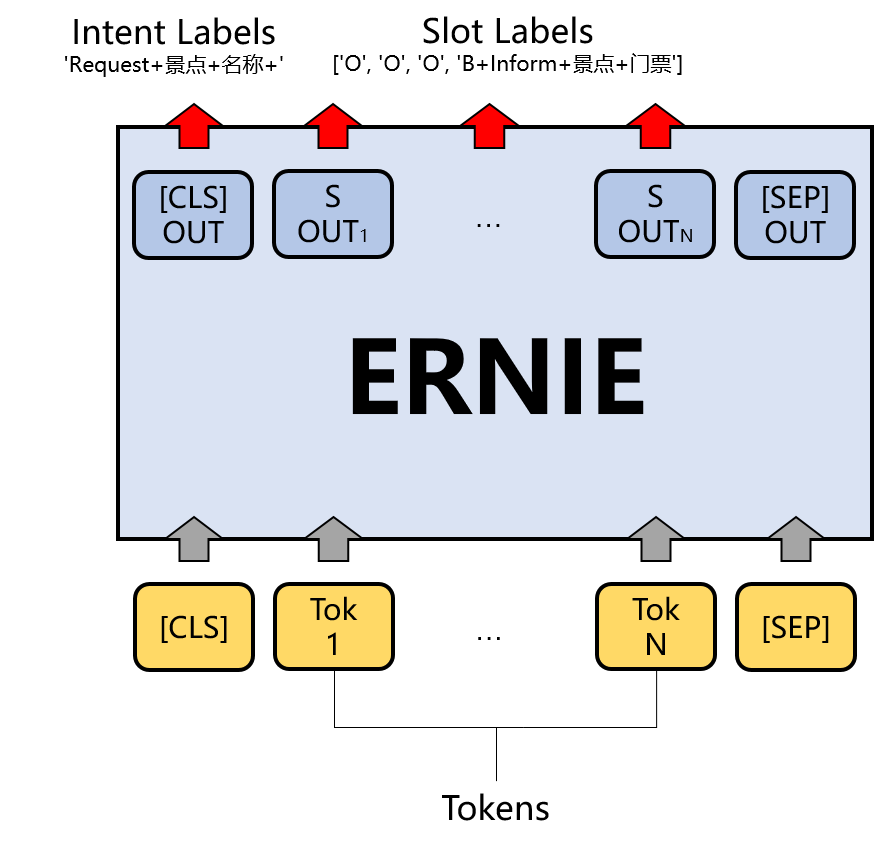
本实践设计方案将基于ERNIE,在CrossWOZ数据集上完成意图识别和槽位填充任务。在本实践中,意图识别和槽位填充本质上是一个句子分类任务和一个序列标注任务,如图1所示,CLS token位置的输出将被用来进行语句分类,文本串的实际token将被用来进行序列标注任务。在训练过程中,会将两者的loss结合,从而实现意图识别和槽位填充的多任务学习。
2. 数据准备
2.1 数据集介绍
CrossWOZ 是第一个大规模的中国跨域任务导向的数据集。 它包含5个领域,共计6K对话和102K语句,包括酒店、餐厅、景点、地铁和出租车。 此外,语料库包含丰富的用户和系统端对话状态和对话行为的注释。
关于数据集的更多信息请参考论文 CrossWOZ: A Large-Scale Chinese Cross-Domain Task-Oriented Dialogue Dataset 。
2.2 数据加载
接下来,我们将关于词典以及训练、评估数据集加载到内存中。然后对目前的数据集中的intent标签数量进行统计,其将用于后续的intent损失计算中。import paddle
import os
import ast
import argparse
import warnings
import numpy as np
from functools import partial
from seqeval.metrics.sequence_labeling import get_entities
from utils.utils import set_seed
from utils.data import read, load_dict, convert_example_to_feature
from utils.metric import SeqEntityScore, MultiLabelClassificationScore
import paddle
import paddle.nn.functional as F
from paddlenlp.datasets import load_dataset
from paddlenlp.transformers import ErnieTokenizer, ErnieModel, LinearDecayWithWarmup
from paddlenlp.data import Stack, Pad, Tuple
intent_dict_path = “./dataset/intent_labels.json”
slot_dict_path = “./dataset/slot_labels.json”
train_path = “./dataset/train.json”
dev_path = “./dataset/test.json”
#load and process data
intent2id, id2intent = load_dict(intent_dict_path)
slot2id, id2slot = load_dict(slot_dict_path)
train_ds = load_dataset(read, data_path=train_path, lazy=False)
dev_ds = load_dataset(read, data_path=dev_path, lazy=False)
#compute intent weight
intent_weight = [1] * len(intent2id)
for example in train_ds:
for intent in example[“intent_labels”]:
intent_weight[intent2id[intent]] += 1
for intent, intent_id in intent2id.items():
neg_pos = (len(train_ds) - intent_weight[intent_id]) / intent_weight[intent_id]
intent_weight[intent_id] = np.log10(neg_pos)
intent_weight = paddle.to_tensor(intent_weight)
2.3 将数据转换成特征形式
接下来,我们将数据转换成适合输入模型的特征形式,即将文本字符串数据转换成字典id的形式。这里我们要加载paddleNLP中的ErnieTokenizer,其将帮助我们完成这个字符串到字典id的转换。model_name = “ernie-1.0”
max_seq_len = 512
batch_size = 32
tokenizer = ErnieTokenizer.from_pretrained(model_name)
trans_func = partial(convert_example_to_feature, tokenizer=tokenizer,
slot2id=slot2id, intent2id=intent2id, pad_default_tag=“O”,
max_seq_len=max_seq_len)
train_ds = train_ds.map(trans_func, lazy=False)
dev_ds = dev_ds.map(trans_func, lazy=False)
2.4 构造DataLoader
接下来,我们需要构造DataLoader,该DataLoader将支持以batch的形式将数据进行划分,从而以batch的形式训练相应模型。batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id),
Pad(axis=0, pad_val=tokenizer.pad_token_type_id),
Stack(dtype=“float32”),
Pad(axis=0, pad_val=slot2id[“O”], dtype=“int64”),
):fn(samples)
train_batch_sampler = paddle.io.BatchSampler(train_ds, batch_size=batch_size, shuffle=True)
dev_batch_sampler = paddle.io.BatchSampler(dev_ds, batch_size=batch_size, shuffle=False)
train_loader = paddle.io.DataLoader(dataset=train_ds,
batch_sampler=train_batch_sampler, collate_fn=batchify_fn,
return_list=True)
dev_loader = paddle.io.DataLoader(dataset=dev_ds, batch_sampler=dev_batch_sampler, collate_fn=batchify_fn, return_list=True)
3. 模型构建
本案例中,我们将基于ERNIE实现图1所展示的意图识别和槽位填充功能。具体来讲,我们将处理好的文本数据输入ERNIE模型中,ERNIE将会对文本的每个token进行编码,产生对应向量序列,然后根据CLS位置的token向量进行意图识别任务,根据后续的位置文本token向量进行槽位填充任务。相应代码如下。import
paddle
from paddle import nn
import paddle.nn.functional as F
from paddlenlp.transformers import ErniePretrainedModel
class JointModel(paddle.nn.Layer):
def init(self, ernie, num_slots, num_intents, dropout=None):
super(JointModel, self).init()
self.num_slots = num_slots
self.num_intents = num_intents
self.ernie = ernie self.dropout = nn.Dropout(dropout if dropout is not None else self.ernie.config["hidden_dropout_prob"]) self.intent_hidden = nn.Linear(self.ernie.config["hidden_size"], self.ernie.config["hidden_size"]) self.slot_hidden = nn.Linear(self.ernie.config["hidden_size"], self.ernie.config["hidden_size"]) self.intent_classifier = nn.Linear(self.ernie.config["hidden_size"], self.num_intents) self.slot_classifier = nn.Linear(self.ernie.config["hidden_size"], self.num_slots) def forward(self, token_ids, token_type_ids=None, position_ids=None, attention_mask=None): sequence_output, pooled_output = self.ernie(token_ids, token_type_ids=token_type_ids, position_ids=position_ids, attention_mask=attention_mask) sequence_output = F.relu(self.slot_hidden(self.dropout(sequence_output))) pooled_output = F.relu(self.intent_hidden(self.dropout(pooled_output))) intent_logits = self.intent_classifier(pooled_output) slot_logits = self.slot_classifier(sequence_output) return intent_logits, slot_logits
4. 训练配置
定义模型训练时用到的损失函数,由于本实践是一个多任务学习的方式,所以将会存在意图识别和槽位填充两个loss,在本实践中,我们将两者进行相加作为最终的loss。另外,我们将定义模型训练时的环境,包括:配置训练参数、配置模型参数,定义模型的实例化对象,指定模型训练迭代的优化算法等,相关代码如下。class
JointLoss(paddle.nn.Layer):
def init(self, intent_weight=None):
super(JointLoss, self).init()
self.intent_criterion = paddle.nn.BCEWithLogitsLoss(weight=intent_weight)
self.slot_criterion = paddle.nn.CrossEntropyLoss()
def forward(self, intent_logits, slot_logits, intent_labels, slot_labels): intent_loss = self.intent_criterion(intent_logits, intent_labels) slot_loss = self.slot_criterion(slot_logits, slot_labels) loss = intent_loss + slot_loss return loss# model hyperparameter setting
num_epoch = 10
learning_rate = 2e-5
weight_decay = 0.01
warmup_proportion = 0.1
max_grad_norm = 1.0
log_step = 50
eval_step = 1000
seed = 1000
save_path = “./checkpoint”
#envir setting
set_seed(seed)
use_gpu = True if paddle.get_device().startswith(“gpu”) else False
if use_gpu:
paddle.set_device(“gpu:0”)
ernie = ErnieModel.from_pretrained(model_name)
joint_model = JointModel(ernie, len(slot2id), len(intent2id), dropout=0.1)
num_training_steps = len(train_loader) * num_epoch
lr_scheduler = LinearDecayWithWarmup(learning_rate, num_training_steps, warmup_proportion)
decay_params = [p.name for n, p in joint_model.named_parameters() if not any(nd in n for nd in [“bias”, “norm”])]
grad_clip = paddle.nn.ClipGradByGlobalNorm(max_grad_norm)
optimizer = paddle.optimizer.AdamW(learning_rate=lr_scheduler,
parameters=joint_model.parameters(), weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in decay_params, grad_clip=grad_clip)
joint_loss = JointLoss(intent_weight)
intent_metric = MultiLabelClassificationScore(id2intent)
slot_metric = SeqEntityScore(id2slot)
5. 模型训练
本节我们将定义一个通用的train函数和evaluate函数。在训练过程中,每隔log_steps步打印一次日志,每隔eval_steps步进行评估一次模型,并当意图识别或者槽位抽取任务的指标中任意一方效果更好时,我们将会进行保存模型。相关代码如下: def evaluate(joint_model, data_loader, intent_metric, slot_metric):
joint_model.eval() intent_metric.reset() slot_metric.reset() for idx, batch_data in enumerate(data_loader): input_ids, token_type_ids, intent_labels, tag_ids = batch_data intent_logits, slot_logits = joint_model(input_ids, token_type_ids=token_type_ids) # count intent metric intent_metric.update(pred_labels=intent_logits, real_labels=intent_labels) # count slot metric slot_pred_labels = slot_logits.argmax(axis=-1) slot_metric.update(pred_paths=slot_pred_labels, real_paths=tag_ids) intent_results = intent_metric.get_result() slot_results = slot_metric.get_result() return intent_results, slot_results
def train():
# start to train joint_model
global_step, intent_best_f1, slot_best_f1 = 0, 0., 0.
joint_model.train()
for epoch in range(1, num_epoch+1):
for batch_data in train_loader:
input_ids, token_type_ids, intent_labels, tag_ids = batch_data
intent_logits, slot_logits = joint_model(input_ids, token_type_ids=token_type_ids)
loss = joint_loss(intent_logits, slot_logits, intent_labels, tag_ids)
loss.backward()
lr_scheduler.step()
optimizer.step()
optimizer.clear_grad()
if global_step > 0 and global_step % log_step == 0:
print(f"epoch: {epoch} - global_step: {global_step}/{num_training_steps} - loss:{loss.numpy().item():.6f}")
if global_step > 0 and global_step % eval_step == 0:
intent_results, slot_results = evaluate(joint_model, dev_loader, intent_metric, slot_metric)
intent_result, slot_result = intent_results["Total"], slot_results["Total"]
joint_model.train()
intent_f1, slot_f1 = intent_result["F1"], slot_result["F1"]
if intent_f1 > intent_best_f1 or slot_f1 > slot_best_f1:
paddle.save(joint_model.state_dict(), f"{save_path}/best.pdparams")
if intent_f1 > intent_best_f1:
print(f"intent best F1 performence has been updated: {intent_best_f1:.5f} --> {intent_f1:.5f}")
intent_best_f1 = intent_f1
if slot_f1 > slot_best_f1:
print(f"slot best F1 performence has been updated: {slot_best_f1:.5f} --> {slot_f1:.5f}")
slot_best_f1 = slot_f1
print(f'intent evalution result: precision: {intent_result["Precision"]:.5f}, recall: {intent_result["Recall"]:.5f}, F1: {intent_result["F1"]:.5f}, current best {intent_best_f1:.5f}')
print(f'slot evalution result: precision: {slot_result["Precision"]:.5f}, recall: {slot_result["Recall"]:.5f}, F1: {slot_result["F1"]:.5f}, current best {slot_best_f1:.5f}\n')
global_step += 1train()
6. 模型推理
实现一个模型预测的函数,实现任意输入一串文本描述,如:“华为手机已经降价,3200万像素只需千元,性价比小米无法比!”,期望能够输出这段描述蕴含的事件。首先我们先加载训练好的模型参数,然后进行推理。相关代码如下。 # load model
model_path = “./checkpoint/best.pdparams”
loaded_state_dict = paddle.load(model_path)
ernie = ErnieModel.from_pretrained(model_name)
joint_model = JointModel(ernie, len(slot2id), len(intent2id), dropout=0.1)
joint_model.load_dict(loaded_state_dict)def predict(input_text, joint_model, tokenizer, id2intent, id2slot):
joint_model.eval()
splited_input_text = list(input_text)
features = tokenizer(splited_input_text, is_split_into_words=True, max_seq_len=max_seq_len, return_length=True)
input_ids = paddle.to_tensor(features["input_ids"]).unsqueeze(0)
token_type_ids = paddle.to_tensor(features["token_type_ids"]).unsqueeze(0)
seq_len = features["seq_len"]
intent_logits, slot_logits = joint_model(input_ids, token_type_ids=token_type_ids)
# parse intent labels
intent_labels = [id2intent[idx] for idx, v in enumerate(intent_logits.numpy()[0]) if v > 0]
# parse slot labels
slot_pred_labels = slot_logits.argmax(axis=-1).numpy()[0][1:(seq_len)-1]
slot_labels = []
for idx in slot_pred_labels:
slot_label = id2slot[idx]
if slot_label != "O":
slot_label = list(id2slot[idx])
slot_label[1] = "-"
slot_label = "".join(slot_label)
slot_labels.append(slot_label)
slot_entities = get_entities(slot_labels)
# print result
if intent_labels:
print("intents: ", ",".join(intent_labels))
else:
print("intents: ", "无")
for slot_entity in slot_entities:
entity_name, start, end = slot_entity
print(f"{entity_name}: ", "".join(splited_input_text[start:end+1]))input_text = “你好,您可以选择故宫,八达岭长城,颐和园或者红砖美术馆。”
predict(input_text, joint_model, tokenizer, id2intent, id2slot)
7. 更多深度学习资源
7.1 一站式深度学习平台awesome-DeepLearning
深度学习入门课
深度学习百问

特色课

产业实践
PaddleEdu使用过程中有任何问题欢迎在awesome-DeepLearning提issue,同时更多深度学习资料请参阅飞桨深度学习平台。
记得点个Star⭐收藏噢~~
