1. 项目概述
本项目主要介绍如何使用飞桨自然语言处理开发库PaddleNLP完成快递单信息抽取:从用户提供的快递单中,抽取姓名、电话、省、市、区、详细地址等内容,形成结构化信息,如 图1 所示,辅助物流行业从业者进行有效信息的提取,从而降低客户填单的成本。

技术难点
从物流信息中抽取想要的关键信息,实际上是自然语言处理中的实体抽取任务,这类任务在产业应用时通常会面临如下技术难点:
实体类别多,任务复杂度高
同一名词可能对应多个实体类别,如“蜗牛”。
不少实体词与普通用语相同,尤其作品名。
此外,实体类别多,任务复杂度较高,如 图2 列举了部分实体类型。实际的实体类型依业务决定。

实体词往往稀疏低频
人名在语料出现频次高,但不同人名出现频次有限
大多垂类实体词在通用语料出现频次低。
特定业务场景中标注数据集较少,需要一定的成本标注,如果数据集质量差或样本量过少,精度会比较低。
2. 方案设计
2.1 模型选取
针对实体信息抽取技术,有如下三种方案:
符号主义 —— 字符串匹配
需要构建词典,穷举所有地址、姓名等信息,但无法发现新词、简称等。统计语言模型(Word-based Generative Model)- n-gram概率/最大概率路径
需要构建词典及词频,但无法发现新词、简称等。序列标注(Character-based Discriminative Model)
需要标注数据,效果好; 有两类实现方法:一是基于统计的模型:HMM、MEMM、CRF,这类方法需要关注特征工程;二是深度学习方法:RNN、LSTM、GRU、CRF、RNN+CRF…
本案例采用序列标注的方式,更加灵活、通用。
我们首先要定义好需要抽取哪些字段。
比如现在拿到一个快递单,可以作为我们的模型输入,例如“张三18625584663广东省深圳市南山区学府路东百度国际大厦”,那么序列标注模型的目的就是识别出其中的“张三”为人名(用符号 P 表示),“18625584663”为电话名(用符号 T 表示),“广东省深圳市南山区百度国际大厦”分别是 1-4 级的地址(分别用 A1~A4 表示,可以释义为省、市、区、街道)。
这是一个典型的命名实体识别(Named Entity Recognition,NER)场景,各实体类型及相应符号表示见下表:
| 抽取实体/字段 | 符号 | 抽取结果 |
|---|---|---|
| 姓名 | P | 张三 |
| 电话 | T | 18625584663 |
| 省 | A1 | 广东省 |
| 市 | A2 | 深圳市 |
| 区 | A3 | 南山区 |
| 详细地址 | A4 | 百度国际大厦 |
在序列标注任务中,一般会定义一个标签集合,来表示所以可能取到的预测结果。在本案例中,针对需要被抽取的“姓名、电话、省、市、区、详细地址”等实体,标签集合可以定义为:
label = {P-B, P-I, T-B, T-I, A1-B, A1-I, A2-B, A2-I, A3-B, A3-I, A4-B, A4-I, O}
每个标签的定义分别为:
| 标签 | 定义 |
|---|---|
| P-B | 姓名起始位置 |
| P-I | 姓名中间位置或结束位置 |
| T-B | 电话起始位置 |
| T-I | 电话中间位置或结束位置 |
| A1-B | 省份起始位置 |
| A1-I | 省份中间位置或结束位置 |
| A2-B | 城市起始位置 |
| A2-I | 城市中间位置或结束位置 |
| A3-B | 县区起始位置 |
| A3-I | 县区中间位置或结束位置 |
| A4-B | 详细地址起始位置 |
| A4-I | 详细地址中间位置或结束位置 |
| O | 无关字符 |
注意每个标签的结果只有 B、I、O 三种,这种标签的定义方式叫做 BIO 体系,也有稍麻烦一点的 BIESO 体系,这里不做展开。其中 B 表示一个标签类别的开头,比如 P-B 指的是姓名的开头;相应的,I 表示一个标签的延续。
对于句子“张三18625584663广东省深圳市南山区百度国际大厦”,每个汉字及对应标签为:

注意到“张“,”三”在这里表示成了“P-B” 和 “P-I”,“P-B”和“P-I”合并成“P” 这个标签。这样重新组合后可以得到以下信息抽取结果:
| 张三 | 18625584663 | 广东省 | 深圳市 | 南山区 | 百度国际大厦 |
|---|---|---|---|---|---|
| P | T | A1 | A2 | A3 | A4 |
2.2 模型介绍
2.2.1 循环神经网络 - 门控循环单元(GRU,Gate Recurrent Unit)
BIGRU是一种经典的循环神经网络(RNN,Recurrent Neural Network),用于对句子等序列信息进行建模。这里我们重点解释下其概念和相关原理。一个 RNN 的示意图如下所示,
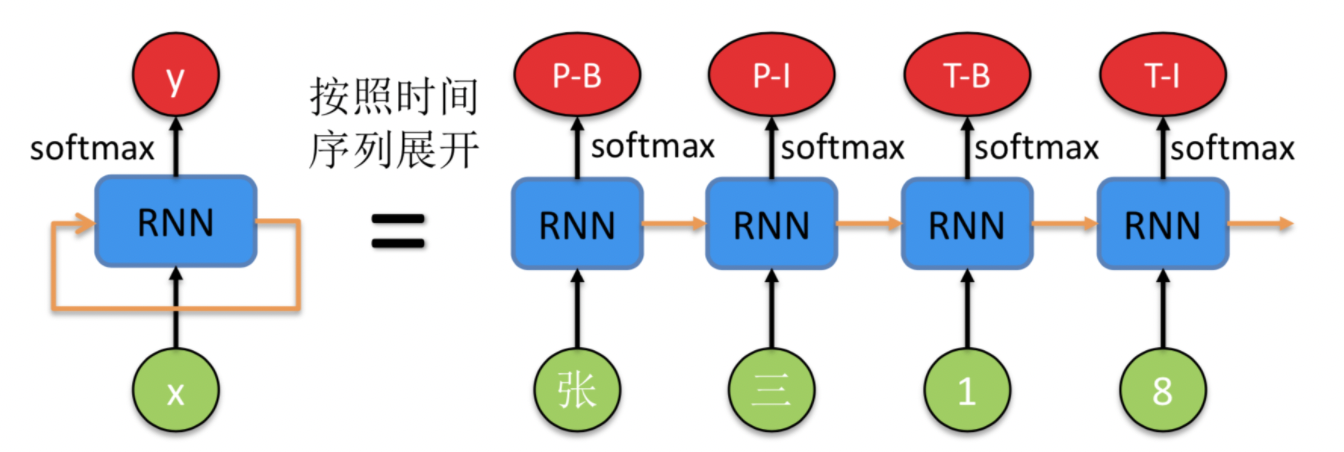
左边是原始的 RNN,可以看到绿色的点代码输入 x,红色的点代表输出 y,中间的蓝色是 RNN 模型部分。橙色的箭头由自身指向自身,表示 RNN 的输入来自于上时刻的输出,这也是为什么名字中带有循环(Recurrent)这个词。
右边是按照时间序列展开的示意图,注意到蓝色的 RNN 模块是同一个,只不过在不同的时刻复用了。这时候能够清晰地表示序列标注模型的输入输出。
GRU为了解决长期记忆和反向传播中梯度问题而提出来的,和LSTM一样能够有效对长序列建模,且GRU训练效率更高。
2.2.2 条件随机场(CRF,Conditional Random Fields)
长句子的问题解决了,序列标注任务的另外一个问题也亟待解决,即标签之间的依赖性。举个例子,我们预测的标签一般不会出现 P-B,T-I 并列的情况,因为这样的标签不合理,也无法解析。无论是 RNN 还是 LSTM 都只能尽量不出现,却无法从原理上避免这个问题。下面要提到的条件随机场(CRF,Conditional Random Field)却很好的解决了这个问题。
条件随机场这个模型属于概率图模型中的无向图模型,这里我们不做展开,只直观解释下该模型背后考量的思想。一个经典的链式 CRF 如下图所示,
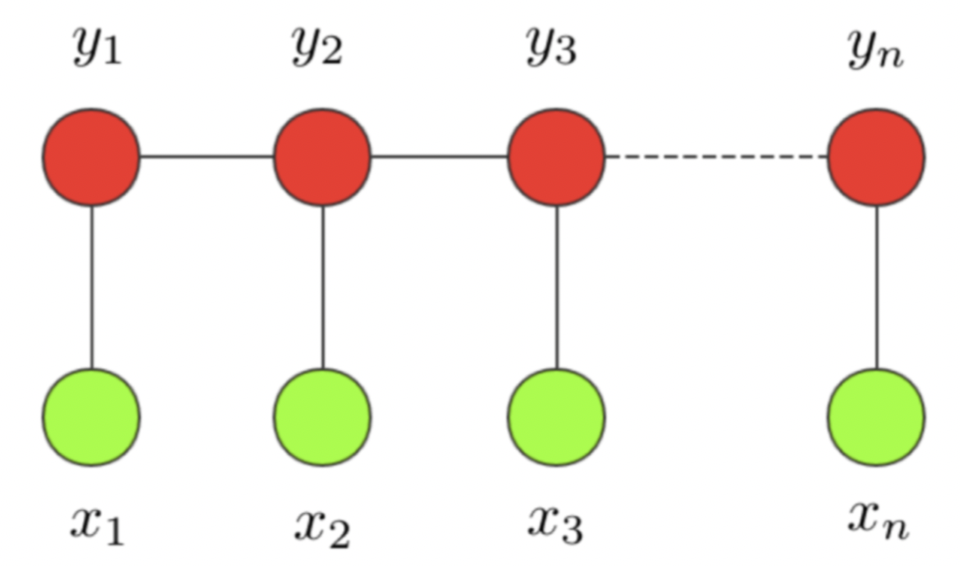
CRF 本质是一个无向图,其中绿色点表示输入,红色点表示输出。点与点之间的边可以分成两类,一类是 xx 与 yy 之间的连线,表示其相关性;另一类是相邻时刻的 yy 之间的相关性。也就是说,在预测某时刻 yy 时,同时要考虑相邻的标签解决。当 CRF 模型收敛时,就会学到类似 P-B 和 T-I 作为相邻标签的概率非常低。
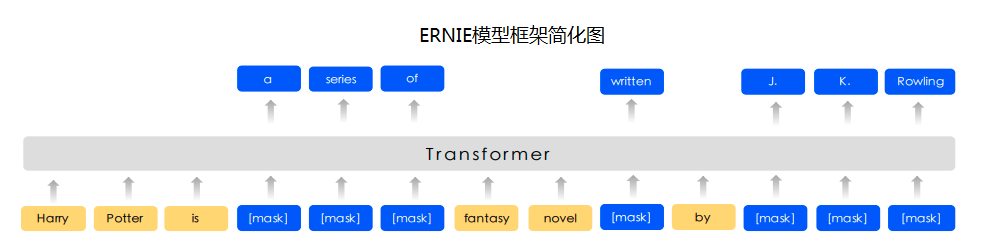
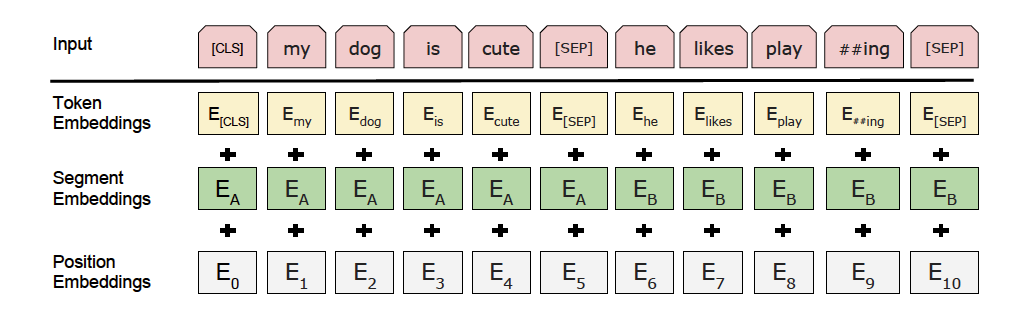
2.2.3 预训练模型 (Ernie、Ernie-Gram)
除了GRU+CRF方案外,我们也可以使用预训练模型,将序列信息抽取问题,建模成字符级分类问题。这里我们采用强大的语义模型ERNIE,完成字符级分类任务。
2.3 评估指标
信息抽取的通用评测指标:Precision、Recall、F1值。
例子:希望抽取10个信息,实际抽取12个,其中有9个是对的

3. 代码实现
3.1 数据准备
采取的是快递单数据集,这份数据除姓名、人名、地名之外,无其他信息。采用BIO方式标注训练集,由于仅含实体信息,所以数据集无“O”(非实体)标识。训练集中除第一行是 text_a\tlabel,后面的每行数据都是由两列组成,以制表符分隔,第一列是 utf-8 编码的中文文本,以 \002 分割,第二列是对应序列标注的结果,以 \002 分割。 !wc -l ./express_ner/train.txt
!wc -l ./express_ner/dev.txt
!wc -l ./express_ner/test.txt
!head -10 ./express_ner/train.txt# 实体标签
!cat ./conf/tag.dic
3.2 模型组网、训练、评估、预测
本项目基于PaddleNLP NER example的代码进行修改,分别基于基本组网单元GRU、CRF和预训练模型,实现了多个方案。
我们以快递单信息抽取为例,介绍如何使用PaddleNLP搭建网络。
方案1: RNN类网络BiGRU、CRF、ViterbiDecoder。
方案2: Ernie
方案3:Ernie+CRF
方案4:Ernie-Gram
方案5:Ernie-Gram+CRFAI Studio平台默认安装了Paddle和PaddleNLP,并定期更新版本。 如需手动更新Paddle,可参考飞桨安装说明,安装相应环境下最新版飞桨框架。
使用如下命令确保安装最新版PaddleNLP:!pip install --upgrade paddlenlp -i https://pypi.org/simple
GRU + CRF
!python run_bigru_crf.py
‘’’
eval begin…
step 1/6 - loss: 0.0000e+00 - precision: 0.9896 - recall: 0.9948 - f1: 0.9922 - 121ms/step
step 2/6 - loss: 0.0000e+00 - precision: 0.9896 - recall: 0.9948 - f1: 0.9922 - 125ms/step
step 3/6 - loss: 20.9767 - precision: 0.9861 - recall: 0.9895 - f1: 0.9878 - 123ms/step
step 4/6 - loss: 0.0000e+00 - precision: 0.9805 - recall: 0.9869 - f1: 0.9837 - 123ms/step
step 5/6 - loss: 0.0000e+00 - precision: 0.9782 - recall: 0.9843 - f1: 0.9812 - 122ms/step
step 6/6 - loss: 0.0000e+00 - precision: 0.9740 - recall: 0.9791 - f1: 0.9765 - 123ms/step
eval samples: 192
‘’’
Ernie
!python run_ernie.py
‘’’
epoch:8 - step:72 - loss: 0.038532
eval precision: 0.974124 - recall: 0.981497 - f1: 0.977796
epoch:9 - step:73 - loss: 0.031000
epoch:9 - step:74 - loss: 0.033214
epoch:9 - step:75 - loss: 0.034606
epoch:9 - step:76 - loss: 0.038763
epoch:9 - step:77 - loss: 0.033273
epoch:9 - step:78 - loss: 0.031058
epoch:9 - step:79 - loss: 0.028151
epoch:9 - step:80 - loss: 0.030707
eval precision: 0.976608 - recall: 0.983179 - f1: 0.979883
‘’’
ErnieGram
!python run_ernie_gram.py
‘’’
epoch:8 - step:72 - loss: 0.030066
eval precision: 0.990764 - recall: 0.992431 - f1: 0.991597
epoch:9 - step:73 - loss: 0.023607
epoch:9 - step:74 - loss: 0.023326
epoch:9 - step:75 - loss: 0.022730
epoch:9 - step:76 - loss: 0.033801
epoch:9 - step:77 - loss: 0.026398
epoch:9 - step:78 - loss: 0.026028
epoch:9 - step:79 - loss: 0.021799
epoch:9 - step:80 - loss: 0.025259
eval precision: 0.990764 - recall: 0.992431 - f1: 0.991597
‘’’
ERNIE + CRF
!python run_ernie_crf.py
‘’’
[eval] Precision: 0.975793 - Recall: 0.983179 - F1: 0.979472
[TRAIN] Epoch:9 - Step:73 - Loss: 0.111980
[TRAIN] Epoch:9 - Step:74 - Loss: 0.152896
[TRAIN] Epoch:9 - Step:75 - Loss: 0.274099
[TRAIN] Epoch:9 - Step:76 - Loss: 0.294602
[TRAIN] Epoch:9 - Step:77 - Loss: 0.231813
[TRAIN] Epoch:9 - Step:78 - Loss: 0.225045
[TRAIN] Epoch:9 - Step:79 - Loss: 0.180734
[TRAIN] Epoch:9 - Step:80 - Loss: 0.171899
[eval] Precision: 0.975000 - Recall: 0.984020 - F1: 0.979489
‘’’
ErnieGram + CRF
!python run_erniegram_crf.py
‘’’
[eval] Precision: 0.992437 - Recall: 0.993272 - F1: 0.992854
[TRAIN] Epoch:9 - Step:73 - Loss: 0.100207
[TRAIN] Epoch:9 - Step:74 - Loss: 0.189141
[TRAIN] Epoch:9 - Step:75 - Loss: 0.051093
[TRAIN] Epoch:9 - Step:76 - Loss: 0.230366
[TRAIN] Epoch:9 - Step:77 - Loss: 0.271885
[TRAIN] Epoch:9 - Step:78 - Loss: 0.342371
[TRAIN] Epoch:9 - Step:79 - Loss: 0.050146
[TRAIN] Epoch:9 - Step:80 - Loss: 0.257951
[eval] Precision: 0.990764 - Recall: 0.992431 - F1: 0.991597
‘’’
4. 部署
4.1 动转静导出模型
import os
import paddle
import paddlenlp
from utils import load_dict
label_vocab = load_dict(’./conf/tag.dic’)
model = paddlenlp.transformers.ErnieForTokenClassification.from_pretrained(“ernie-1.0”, num_classes=len(label_vocab))
params_path = ‘./ernie_result/model_80.pdparams’
state_dict = paddle.load(params_path)
model.set_dict(state_dict)
print(“Loaded parameters from %s” % params_path)
model.eval()
model = paddle.jit.to_static(
model,
input_spec=[
paddle.static.InputSpec(
shape=[None, None], dtype=“int64”), # input_ids
paddle.static.InputSpec(
shape=[None, None], dtype=“int64”) # segment_ids
])
output_path = ‘./ernie_result’
save_path = os.path.join(output_path, “inference”)
paddle.jit.save(model, save_path)
4.2 使用推理库预测
获得静态图模型之后,我们使用Paddle Inference进行预测部署。Paddle Inference是飞桨的原生推理库,作用于服务器端和云端,提供高性能的推理能力。
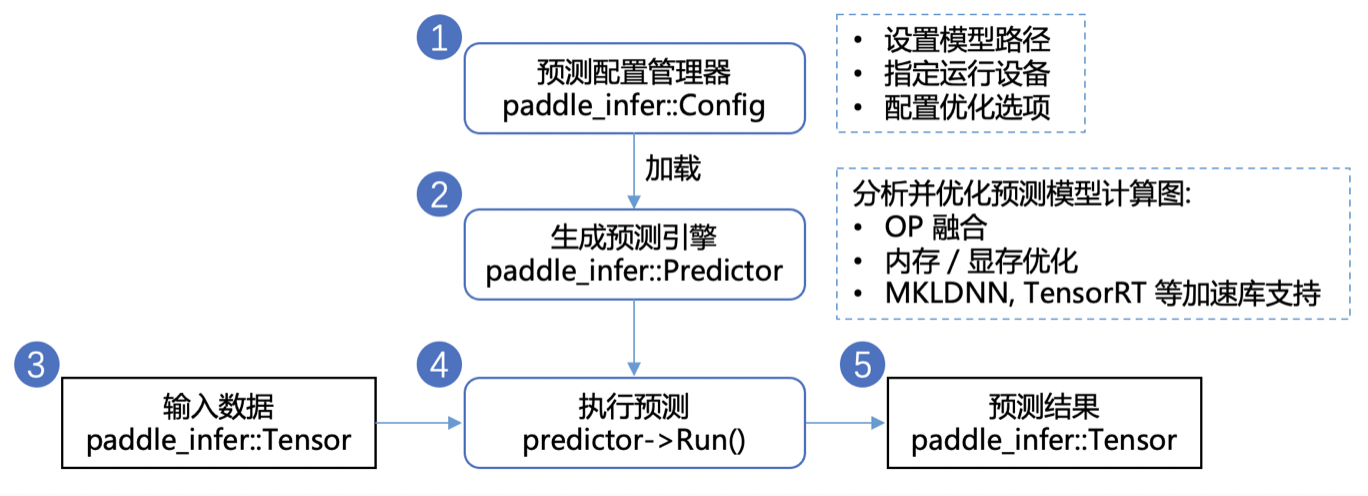
Paddle Inference 采用 Predictor 进行预测。Predictor 是一个高性能预测引擎,该引擎通过对计算图的分析,完成对计算图的一系列的优化(如OP的融合、内存/显存的优化、 MKLDNN,TensorRT 等底层加速库的支持等),能够大大提升预测性能。另外Paddle Inference提供了Python、C++、GO等多语言的API,可以根据实际环境需要进行选择,例如使用 Paddle Inference 开发 Python 预测程序可参考示例,相关API已安装在Paddle包,直接使用即可。
PaddleNLP更多教程
自定义数据集实现文本多分类任务# 加入交流群,一起学习吧