情感分析系统也有同款视频课程上线啦,课程直通车点击这里情感分析旨在对带有情感色彩的主观性文本进行分析、处理、归纳和推理,其广泛应用于消费决策、舆情分析、个性化推荐等领域,具有很高的商业价值。
依托百度领先的情感分析技术,食行生鲜自动生成菜品评论标签辅助用户购买,并指导运营采购部门调整选品和促销策略;房天下向购房者和开发商直观展示楼盘的用户口碑情况,并对好评楼盘置顶推荐;国美搭建服务智能化评分系统,客服运营成本减少40%,负面反馈处理率100%。
情感分析相关的任务有语句级情感分析、评论对象抽取、观点抽取等等。一般来讲,被人们所熟知的情感分析任务是语句级别的情感分析,该任务是在宏观上去分析整句话的感情色彩,其粒度可能相对比较粗。
因为在人们进行评论的时候,往往针对某一产品或服务进行多个属性的评论,对每个属性的评论可能也会褒贬不一,因此针对属性级别的情感分析在真实的场景中会更加实用,同时更能给到企业用户或商家更加具体的建议。例如这句关于薯片的评论。
这个薯片味道真的太好了,口感很脆,只是包装很一般。
可以看到,顾客在口感、包装和味道 三个属性上对薯片进行了评价,顾客在味道和口感两个方面给出了好评,但是在包装上给出了负面的评价。只有通过这种比较细粒度的分析,商家才能更有针对性的发现问题,进而改进自己的产品或服务。
基于这样的考虑,本项目提出了一种细粒度的情感分析能力,对于给定的文本,首先会抽取该文本中的评论观点,然后分析不同观点的情感极性。
1. 方案设计
那么应该如何细粒度的分析语句中不同方面的评论呢?本实践的解决方案大致分为两个环节,首先需要进行评论观点抽取,接下来,便可以根据该评论观点去分析相应观点的情感极性。
1.1 评论观点抽取
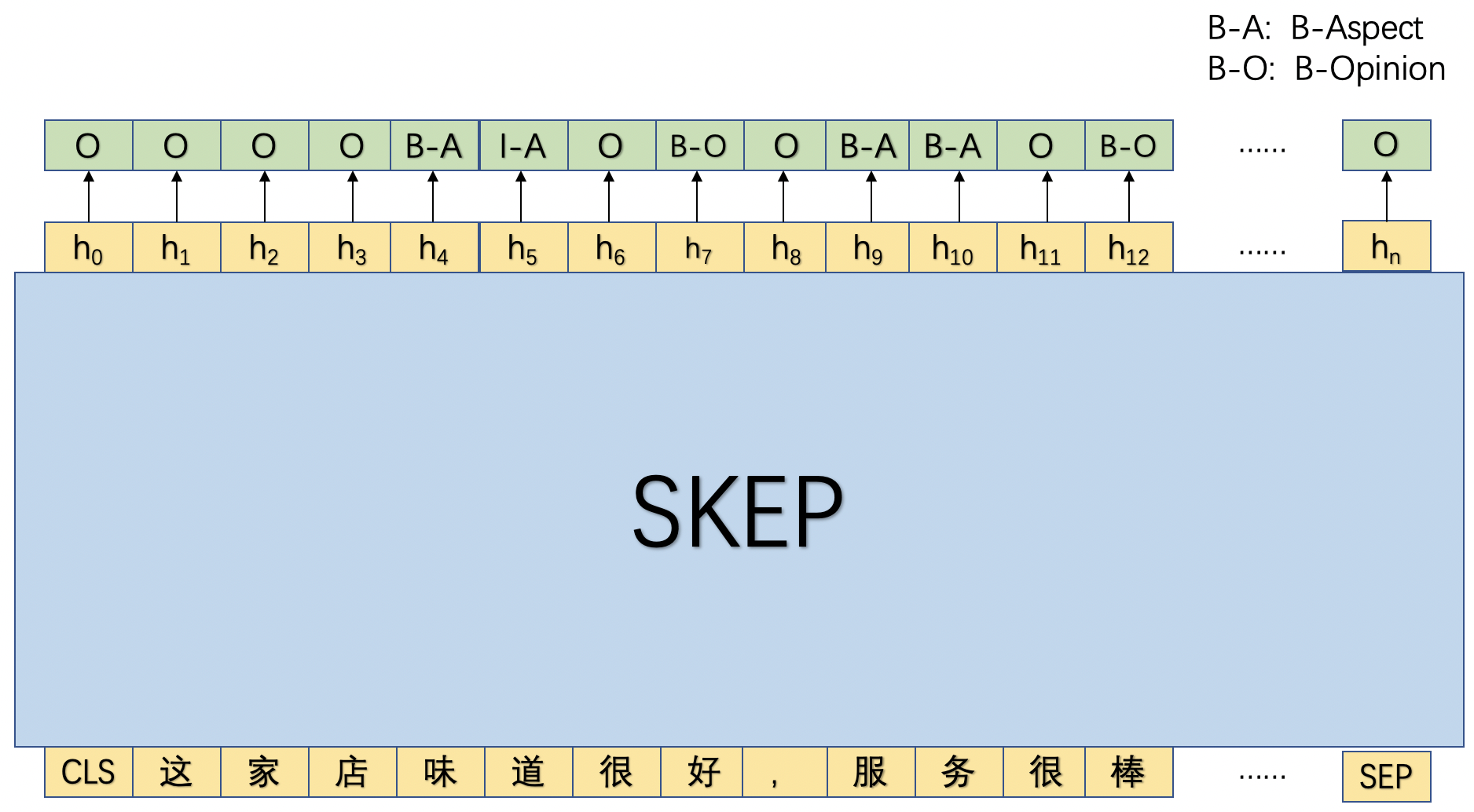
在本实践中,我们将采用序列标注的方式进行评论观点抽取,具体而言,会抽取评论中的属性以及属性对应的观点,为此我们基于BIO的序列标注体系进行了标签的拓展:B-Aspect, I-Aspect, B-Opinion, I-Opinion, O,其中前两者用于标注评论属性,后两者用于标注相应观点。
如图1所示,首先将文本串传入SKEP模型中,利用SKEP模型对该文本串进行语义编码后,然后基于每个位置的输出去预测相应的标签。
1.2 属性级情感分类
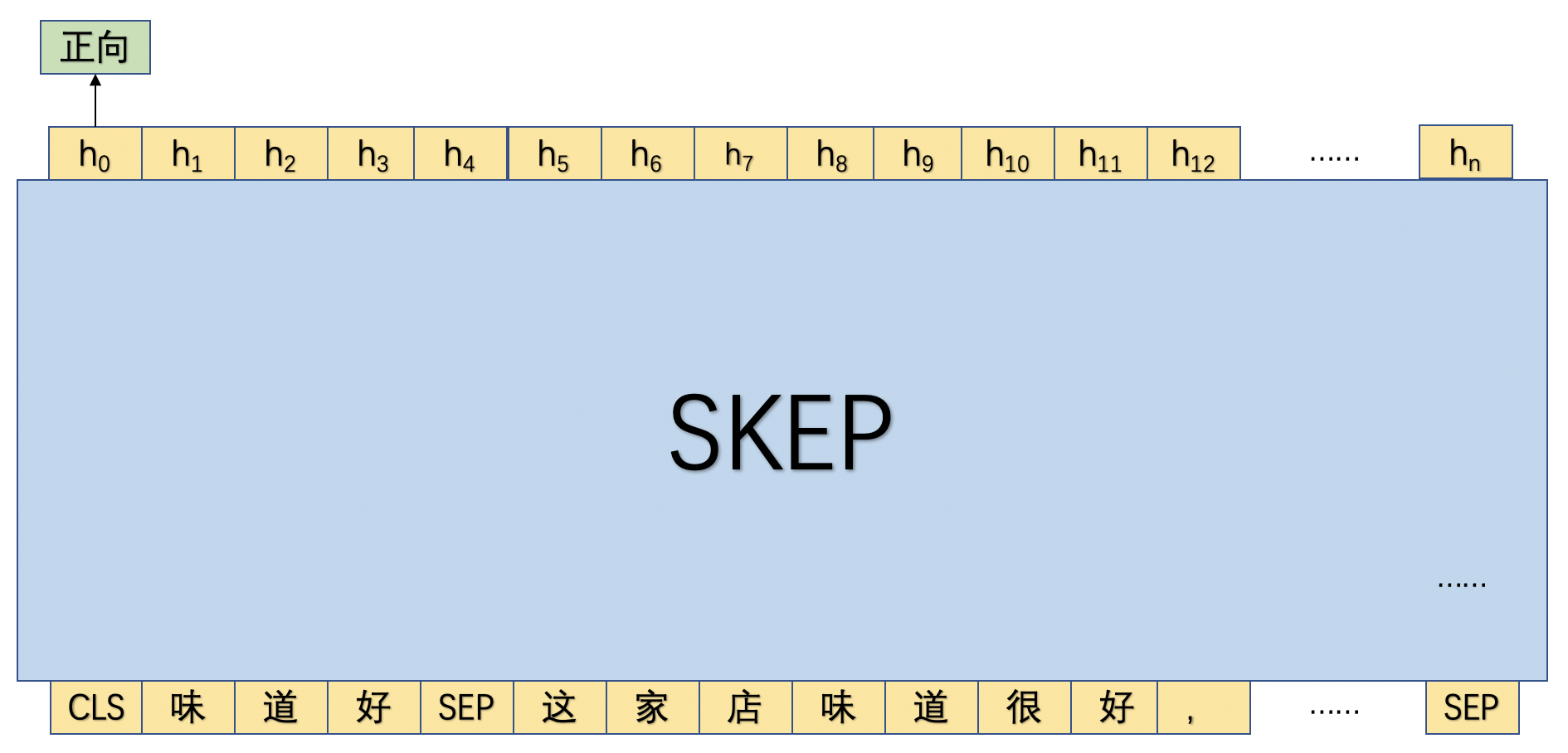
在抽取完评论观点之后,便可以有针对性的对各个属性进行评论。具体来讲,本实践将抽取出的评论属性和评论观点进行拼接,然后和原始语句进行拼接作为一条独立的训练语句。
如图2所示,首先将评论属性和观点词进行拼接为"味道好",然后将"味道好"和原文进行拼接,然后传入SKEP模型,并使用"CLS"位置的向量进行细粒度情感倾向。
2. 评论观点抽取模型
2.1 数据处理
2.1.1 数据集介绍
本实践中包含训练集、评估和测试3项数据集,以及1个标签词典。其中标签词典记录了本实践中用于抽取评论对象和观点词时使用的标签。
另外,本实践将采用序列标注的方式完成此任务,所以本数据集中需要包含两列数据:文本串和相应的序列标签数据,下面给出了一条样本。
服务好,环境好,做出来效果也不错 B-Aspect I-Aspect B-Opinion O B-Aspect I-Aspect B-Opinion O O O O B-Aspect I-Aspect O B-Opinion I-Opinion
2.2.2 数据加载
本节我们将训练、评估和测试数据集,以及标签词典加载到内存中。相关代码如下:import os
import argparse
from functools import partial
import paddle
import paddle.nn.functional as F
from paddlenlp.metrics import Chunkevaluator
from paddlenlp.datasets import load_dataset
from paddlenlp.data import Pad, Stack, Tuple
from paddlenlp.transformers import SkepTokenizer, SkepModel, LinearDecayWithWarmup
from utils.utils import set_seed
from utils import data_ext, data_cls
train_path = “./data/data121190/train_ext.txt”
dev_path = “./data/data121190/dev_ext.txt”
test_path = “./data/data121190/test_ext.txt”
label_path = “./data/data121190/label_ext.dict”
#load and process data
label2id, id2label = data_ext.load_dict(label_path)
train_ds = load_dataset(data_ext.read, data_path=train_path, lazy=False)
dev_ds = load_dataset(data_ext.read, data_path=dev_path, lazy=False)
test_ds = load_dataset(data_ext.read, data_path=test_path, lazy=False)
#print examples
for example in train_ds[9:11]:
print(example)
2.2.3 将数据转换成特征形式
在将数据加载完成后,接下来,我们将各项数据集转换成适合输入模型的特征形式,即将文本字符串数据转换成字典id的形式。这里我们要加载paddleNLP中的SkepTokenizer,其将帮助我们完成这个字符串到字典id的转换。model_name
= “skep_ernie_1.0_large_ch”
batch_size = 8
max_seq_len = 512
tokenizer = SkepTokenizer.from_pretrained(model_name)
trans_func = partial(data_ext.convert_example_to_feature, tokenizer=tokenizer, label2id=label2id, max_seq_len=max_seq_len)
train_ds = train_ds.map(trans_func, lazy=False)
dev_ds = dev_ds.map(trans_func, lazy=False)
test_ds = test_ds.map(trans_func, lazy=False)
#print examples
for example in train_ds[9:11]:
print("input_ids: ", example[0])
print("token_type_ids: ", example[1])
print("seq_len: ", example[2])
print("label: ", example[3])
print()
2.2.4 构造DataLoader
接下来,我们需要根据加载至内存的数据构造DataLoader,该DataLoader将支持以batch的形式将数据进行划分,从而以batch的形式训练相应模型。batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id),
Pad(axis=0, pad_val=tokenizer.pad_token_type_id),
Stack(dtype=“int64”),
Pad(axis=0, pad_val= -1)
): fn(samples)
train_batch_sampler = paddle.io.BatchSampler(train_ds, batch_size=batch_size, shuffle=True)
dev_batch_sampler = paddle.io.BatchSampler(dev_ds, batch_size=batch_size, shuffle=False)
test_batch_sampler = paddle.io.BatchSampler(test_ds, batch_size=batch_size, shuffle=False)
train_loader = paddle.io.DataLoader(train_ds, batch_sampler=train_batch_sampler, collate_fn=batchify_fn)
dev_loader = paddle.io.DataLoader(dev_ds, batch_sampler=dev_batch_sampler, collate_fn=batchify_fn)
test_loader = paddle.io.DataLoader(test_ds, batch_sampler=test_batch_sampler, collate_fn=batchify_fn)
2.3 模型构建
本案例中,我们将基于SKEP模型实现图1所展示的评论观点抽取功能。具体来讲,我们将处理好的文本数据输入SKEP模型中,SKEP将会对文本的每个token进行编码,产生对应向量序列。接下来,我们将基于该向量序列进行预测每个位置上的输出标签。相应代码如下。
class SkepForTokenClassification(paddle.nn.Layer):
def init(self, skep, num_classes=2, dropout=None):
super(SkepForTokenClassification, self).init()
self.num_classes = num_classes
self.skep = skep
self.dropout = paddle.nn.Dropout(dropout if dropout is not None else self.skep.config[“hidden_dropout_prob”])
self.classifier = paddle.nn.Linear(self.skep.config[“hidden_size”], num_classes)
def forward(self, input_ids, token_type_ids=None, position_ids=None, attention_mask=None): sequence_output, _ = self.skep(input_ids, token_type_ids=token_type_ids, position_ids=position_ids, attention_mask=attention_mask) sequence_output = self.dropout(sequence_output) logits = self.classifier(sequence_output) return logits
2.4 训练配置
接下来,定义情感分析模型训练时的环境,包括:配置训练参数、配置模型参数,定义模型的实例化对象,指定模型训练迭代的优化算法等,相关代码如下。
#model hyperparameter setting
num_epoch = 3
learning_rate = 3e-5
weight_decay = 0.01
warmup_proportion = 0.1
max_grad_norm = 1.0
log_step = 20
eval_step = 100
seed = 1000
checkpoint = “./checkpoint/”
set_seed(seed)
use_gpu = True if paddle.get_device().startswith(“gpu”) else False
if use_gpu:
paddle.set_device(“gpu:0”)
if not os.path.exists(checkpoint):
os.mkdir(checkpoint)
skep = SkepModel.from_pretrained(model_name)
model = SkepForTokenClassification(skep, num_classes=len(label2id))
num_training_steps = len(train_loader) * num_epoch
lr_scheduler = LinearDecayWithWarmup(learning_rate=learning_rate, total_steps=num_training_steps, warmup=warmup_proportion)
decay_params = [p.name for n, p in model.named_parameters() if not any(nd in n for nd in [“bias”, “norm”])]
grad_clip = paddle.nn.ClipGradByGlobalNorm(max_grad_norm)
optimizer = paddle.optimizer.AdamW(learning_rate=lr_scheduler,
parameters=model.parameters(), weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in decay_params, grad_clip=grad_clip)
metric = Chunkevaluator(label2id.keys())
2.5 模型训练与测试
本节我们将定义一个train函数和evaluate函数,其将分别进行训练和评估模型。在训练过程中,每隔log_steps步打印一次日志,每隔eval_steps步进行评估一次模型,并始终保存验证效果最好的模型。相关代码如下:def evaluate(model, data_loader, metric):
model.eval() metric.reset() for idx, batch_data in enumerate(data_loader): input_ids, token_type_ids, seq_lens, labels = batch_data logits = model(input_ids, token_type_ids=token_type_ids) # count metric predictions = logits.argmax(axis=2) num_infer_chunks, num_label_chunks, num_correct_chunks = metric.compute(seq_lens, predictions, labels) metric.update(num_infer_chunks.numpy(), num_label_chunks.numpy(), num_correct_chunks.numpy()) precision, recall, f1 = metric.accumulate() return precision, recall, f1
def train():
# start to train model
global_step, best_f1 = 1, 0.
model.train()
for epoch in range(1, num_epoch+1):
for batch_data in train_loader():
input_ids, token_type_ids, _, labels = batch_data
# logits: batch_size, seql_len, num_tags
logits = model(input_ids, token_type_ids=token_type_ids)
loss = F.cross_entropy(logits.reshape([-1, len(label2id)]), labels.reshape([-1]), ignore_index=-1)
loss.backward()
lr_scheduler.step()
optimizer.step()
optimizer.clear_grad()
if global_step > 0 and global_step % log_step == 0:
print(f"epoch: {epoch} - global_step: {global_step}/{num_training_steps} - loss:{loss.numpy().item():.6f}")
if (global_step > 0 and global_step % eval_step == 0) or global_step == num_training_steps:
precision, recall, f1 = evaluate(model, dev_loader, metric)
model.train()
if f1 > best_f1:
print(f"best F1 performence has been updated: {best_f1:.5f} --> {f1:.5f}")
best_f1 = f1
paddle.save(model.state_dict(), f"{checkpoint}/best_ext.pdparams")
print(f'evalution result: precision: {precision:.5f}, recall: {recall:.5f}, F1: {f1:.5f}')
global_step += 1
paddle.save(model.state_dict(), f"{checkpoint}/final_ext.pdparams")train()接下来,我们将加载训练过程中评估效果最好的模型,并使用测试集进行测试。相关代码如下。# load model
model_path = “./checkpoint/best_ext.pdparams”
loaded_state_dict = paddle.load(model_path)
skep = SkepModel.from_pretrained(model_name)
model = SkepForTokenClassification(skep, num_classes=len(label2id))
model.load_dict(loaded_state_dict)# evalute on test data
precision, recall, f1 = evaluate(model, test_loader, metric)
print(f’evalution result: precision: {precision:.5f}, recall: {recall:.5f}, F1: {f1:.5f}’)
3. 属性级情感分类
3.1 数据处理
3.1.1 数据集介绍
本实践中包含训练集、评估和测试3项数据集,以及1个标签词典。其中标签词典记录了两类情感标签:正向和负向。
另外,数据集中需要包含3列数据:文本串和相应的序列标签数据,下面给出了一条样本,其中第1列是情感标签,第2列是评论属性和观点,第3列是原文。
1 口味清淡 口味很清淡,价格也比较公道
3.2.2 数据加载
本节我们将训练、评估和测试数据集,以及标签词典加载到内存中。相关代码如下:import os
import argparse
from functools import partial
import paddle
import paddle.nn.functional as F
from paddlenlp.metrics import AccuracyAndF1
from paddlenlp.datasets import load_dataset
from paddlenlp.data import Pad, Stack, Tuple
from paddlenlp.transformers import SkepTokenizer, SkepModel, LinearDecayWithWarmup
from utils.utils import set_seed, decoding, is_aspect_first, concate_aspect_and_opinion, format_print
from utils import data_ext, data_cls
train_path = “./data/data121242/train_cls.txt”
dev_path = “./data/data121242/dev_cls.txt”
test_path = “./data/data121242/test_cls.txt”
label_path = “./data/data121242/label_cls.dict”
#load and process data
label2id, id2label = data_cls.load_dict(label_path)
train_ds = load_dataset(data_cls.read, data_path=train_path, lazy=False)
dev_ds = load_dataset(data_cls.read, data_path=dev_path, lazy=False)
test_ds = load_dataset(data_cls.read, data_path=test_path, lazy=False)
#print examples
for example in train_ds[:2]:
print(example)
3.2.3 将数据转换成特征形式
在将数据加载完成后,接下来,我们将各项数据集转换成适合输入模型的特征形式,即将文本字符串数据转换成字典id的形式。这里我们要加载paddleNLP中的SkepTokenizer,其将帮助我们完成这个字符串到字典id的转换。model_name
= “skep_ernie_1.0_large_ch”
batch_size = 8
max_seq_len = 512
tokenizer = SkepTokenizer.from_pretrained(model_name)
trans_func = partial(data_cls.convert_example_to_feature, tokenizer=tokenizer, label2id=label2id, max_seq_len=max_seq_len)
train_ds = train_ds.map(trans_func, lazy=False)
dev_ds = dev_ds.map(trans_func, lazy=False)
test_ds = test_ds.map(trans_func, lazy=False)
#print examples
#print examples
for example in train_ds[:2]:
print("input_ids: ", example[0])
print("token_type_ids: ", example[1])
print("seq_len: ", example[2])
print("label: ", example[3])
print()
3.2.4 构造DataLoader
接下来,我们需要根据加载至内存的数据构造DataLoader,该DataLoader将支持以batch的形式将数据进行划分,从而以batch的形式训练相应模型。batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id),
Pad(axis=0, pad_val=tokenizer.pad_token_type_id),
Stack(dtype=“int64”),
Stack(dtype=“int64”)
): fn(samples)
train_batch_sampler = paddle.io.BatchSampler(train_ds, batch_size=batch_size, shuffle=True)
dev_batch_sampler = paddle.io.BatchSampler(dev_ds, batch_size=batch_size, shuffle=False)
test_batch_sampler = paddle.io.BatchSampler(test_ds, batch_size=batch_size, shuffle=False)
train_loader = paddle.io.DataLoader(train_ds, batch_sampler=train_batch_sampler, collate_fn=batchify_fn)
dev_loader = paddle.io.DataLoader(dev_ds, batch_sampler=dev_batch_sampler, collate_fn=batchify_fn)
test_loader = paddle.io.DataLoader(test_ds, batch_sampler=test_batch_sampler, collate_fn=batchify_fn)
3.3 模型构建
本案例中,我们将基于SKEP模型实现图1所展示的评论观点抽取功能。具体来讲,我们将处理好的文本数据输入SKEP模型中,SKEP将会对文本的每个token进行编码,产生对应向量序列。我们使用CLS位置对应的输出向量进行情感分类。相应代码如下。
class SkepForSequenceClassification(paddle.nn.Layer):
def init(self, skep, num_classes=2, dropout=None):
super(SkepForSequenceClassification, self).init()
self.num_classes = num_classes
self.skep = skep
self.dropout = paddle.nn.Dropout(dropout if dropout is not None else self.skep.config[“hidden_dropout_prob”])
self.classifier = paddle.nn.Linear(self.skep.config[“hidden_size”], num_classes)
def forward(self, input_ids, token_type_ids=None, position_ids=None, attention_mask=None): _, pooled_output = self.skep(input_ids, token_type_ids=token_type_ids, position_ids=position_ids, attention_mask=attention_mask) pooled_output = self.dropout(pooled_output) logits = self.classifier(pooled_output) return logits
3.4 训练配置
接下来,定义情感分析模型训练时的环境,包括:配置训练参数、配置模型参数,定义模型的实例化对象,指定模型训练迭代的优化算法等,相关代码如下。
#model hyperparameter setting
num_epoch = 3
learning_rate = 3e-5
weight_decay = 0.01
warmup_proportion = 0.1
max_grad_norm = 1.0
log_step = 20
eval_step = 100
seed = 1000
checkpoint = “./checkpoint/”
set_seed(seed)
use_gpu = True if paddle.get_device().startswith(“gpu”) else False
if use_gpu:
paddle.set_device(“gpu:0”)
if not os.path.exists(checkpoint):
os.mkdir(checkpoint)
skep = SkepModel.from_pretrained(model_name)
model = SkepForSequenceClassification(skep, num_classes=len(label2id))
num_training_steps = len(train_loader) * num_epoch
lr_scheduler = LinearDecayWithWarmup(learning_rate=learning_rate, total_steps=num_training_steps, warmup=warmup_proportion)
decay_params = [p.name for n, p in model.named_parameters() if not any(nd in n for nd in [“bias”, “norm”])]
grad_clip = paddle.nn.ClipGradByGlobalNorm(max_grad_norm)
optimizer = paddle.optimizer.AdamW(learning_rate=lr_scheduler,
parameters=model.parameters(), weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in decay_params, grad_clip=grad_clip)
metric = AccuracyAndF1()
3.5 模型训练与测试
本节我们将定义一个train函数和evaluate函数,其将分别进行训练和评估模型。在训练过程中,每隔log_steps步打印一次日志,每隔eval_steps步进行评估一次模型,并始终保存验证效果最好的模型。相关代码如下:def evaluate(model, data_loader, metric):
model.eval() metric.reset() for batch_data in data_loader: input_ids, token_type_ids, _, labels = batch_data logits = model(input_ids, token_type_ids=token_type_ids) correct = metric.compute(logits, labels) metric.update(correct) accuracy, precision, recall, f1, _ = metric.accumulate() return accuracy, precision, recall, f1
def train():
# start to train model
global_step, best_f1 = 1, 0.
model.train()
for epoch in range(1, num_epoch+1):
for batch_data in train_loader():
input_ids, token_type_ids, _, labels = batch_data
# logits: batch_size, seql_len, num_tags
logits = model(input_ids, token_type_ids=token_type_ids)
loss = F.cross_entropy(logits, labels)
loss.backward()
lr_scheduler.step()
optimizer.step()
optimizer.clear_grad()
if global_step > 0 and global_step % log_step == 0:
print(f"epoch: {epoch} - global_step: {global_step}/{num_training_steps} - loss:{loss.numpy().item():.6f}")
if (global_step > 0 and global_step % eval_step == 0) or global_step == num_training_steps:
accuracy, precision, recall, f1 = evaluate(model, dev_loader, metric)
model.train()
if f1 > best_f1:
print(f"best F1 performence has been updated: {best_f1:.5f} --> {f1:.5f}")
best_f1 = f1
paddle.save(model.state_dict(), f"{checkpoint}/best_cls.pdparams")
print(f'evalution result: accuracy:{accuracy:.5f} precision: {precision:.5f}, recall: {recall:.5f}, F1: {f1:.5f}')
global_step += 1
paddle.save(model.state_dict(), f"{checkpoint}/final_cls.pdparams")train()接下来,我们将加载训练过程中评估效果最好的模型,并使用测试集进行测试。相关代码如下。# load model
model_path = “./checkpoint/best_cls.pdparams”
loaded_state_dict = paddle.load(model_path)
skep = SkepModel.from_pretrained(model_name)
model = SkepForSequenceClassification(skep, num_classes=len(label2id))
model.load_dict(loaded_state_dict)accuracy, precision, recall, f1 = evaluate(model, test_loader, metric)
print(f’evalution result: accuracy:{accuracy:.5f} precision: {precision:.5f}, recall: {recall:.5f}, F1: {f1:.5f}’)
4. 全流程模型推理
在前边的实验过程中,我们完成了基于Demo数据的评论观点抽取模型和属性级情感分类模型训练和评估,并且保存了训练过程中评估效果最好的模型。
但是同时我们也开源了基于全量数据训练好的评论观点抽取模型和属性级情感分类模型,我们可以使用下面的命令进行下载,并基于下载好的模型进行全流程情感分析预测。# 下载评论观点抽取模型
!wget https://bj.bcebos.com/paddlenlp/models/best_ext.pdparams
#下载属性级情感分类模型
!wget https://bj.bcebos.com/paddlenlp/models/best_cls.pdparamslabel_ext_path = “./data/data121190/label_ext.dict”
label_cls_path = “./data/data121242/label_cls.dict”
ext_model_path = “./best_ext.pdparams”
cls_model_path = “./best_cls.pdparams”
#load dict
model_name = “skep_ernie_1.0_large_ch”
ext_label2id, ext_id2label = data_ext.load_dict(label_ext_path)
cls_label2id, cls_id2label = data_cls.load_dict(label_cls_path)
tokenizer = SkepTokenizer.from_pretrained(model_name)
print(“label dict loaded.”)
#load ext model
ext_state_dict = paddle.load(ext_model_path)
ext_skep = SkepModel.from_pretrained(model_name)
ext_model = SkepForTokenClassification(ext_skep, num_classes=len(ext_label2id))
ext_model.load_dict(ext_state_dict)
print(“extraction model loaded.”)
#load cls model
cls_state_dict = paddle.load(cls_model_path)
cls_skep = SkepModel.from_pretrained(model_name)
cls_model = SkepForSequenceClassification(cls_skep, num_classes=len(cls_label2id))
cls_model.load_dict(cls_state_dict)
print(“classification model loaded.”)def predict(input_text, ext_model,
cls_model, tokenizer, ext_id2label, cls_id2label, max_seq_len=512):
ext_model.eval()
cls_model.eval()
# processing input text
encoded_inputs = tokenizer(list(input_text), is_split_into_words=True, max_seq_len=max_seq_len,)
input_ids = paddle.to_tensor([encoded_inputs["input_ids"]])
token_type_ids = paddle.to_tensor([encoded_inputs["token_type_ids"]])
# extract aspect and opinion words
logits = ext_model(input_ids, token_type_ids=token_type_ids)
predictions = logits.argmax(axis=2).numpy()[0]
tag_seq = [ext_id2label[idx] for idx in predictions][1:-1]
aps = decoding(input_text, tag_seq)
# predict sentiment for aspect with cls_model
results = []
for ap in aps:
aspect = ap[0]
opinion_words = list(set(ap[1:]))
aspect_text = concate_aspect_and_opinion(input_text, aspect, opinion_words)
encoded_inputs = tokenizer(aspect_text, text_pair=input_text, max_seq_len=max_seq_len, return_length=True)
input_ids = paddle.to_tensor([encoded_inputs["input_ids"]])
token_type_ids = paddle.to_tensor([encoded_inputs["token_type_ids"]])
logits = cls_model(input_ids, token_type_ids=token_type_ids)
prediction = logits.argmax(axis=1).numpy()[0]
result = {"aspect": aspect, "opinions": opinion_words, "sentiment": cls_id2label[prediction]}
results.append(result)
# print results
format_print(results)max_seq_len = 512
input_text = “环境装修不错,也很干净,前台服务非常好”
predict(input_text, ext_model, cls_model, tokenizer, ext_id2label, cls_id2label, max_seq_len=max_seq_len)
input_text = “蛋糕味道不错,很好吃,店家很耐心,服务也很好,很棒”
predict(input_text, ext_model, cls_model, tokenizer, ext_id2label, cls_id2label, max_seq_len=max_seq_len)
5. 情感分析小模型技术方案
我们基于PaddleNLP开源的PP-MiniLM实现了属性级情感分类模型,PP-MiniLM是基于预训练的中文特色小模型,其使用最新的模型蒸馏技术蒸馏出的6层小模型,模型效果好,运行速度快。下面是PP-MiniLM数据集在7项CLUE任务上的平均值, 详细信息请参考这里。

在使用PP-MiniLM训练好情感分类模型后,我们基于PaddleSlim对模型进行了量化操作,并对SKEP-Large, PP-MiniLM和量化后的PP-MiniLM进行了性能和效果对比,如下图所示。
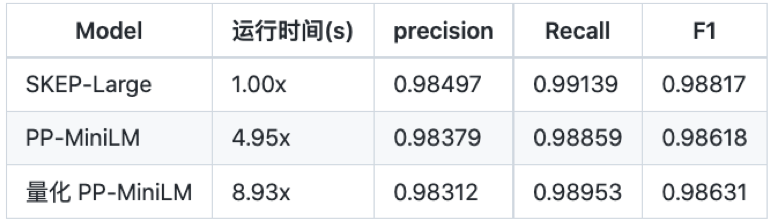
备注:性能测试需要使用安装有 Paddle Inference 预测库的 PaddlePaddle 2.2.1 进行预测,请根据合适的机器环境进行下载安装。若想要得到明显的加速效果,推荐在 NVIDA Tensor Core GPU(如 T4、A10、A100) 上进行测试,若在 V 系列 GPU 卡上测试,由于其不支持 Int8 Tensor Core,将达不到预期的加速效果。以上数据是基于T4进行性能测试结果。
关于情感信息更多的信息请参考PaddleNLP Repo。
6. 引用
[1] H. Tian et al., “SKEP: Sentiment Knowledge Enhanced Pre-training for Sentiment Analysis,” arXiv:2005.05635 [cs], May 2020, Accessed: Nov. 11, 2021.