学习资源
更多的深度学习资料,比如深度学习知识,论文解读,实践案例等,请参考:awesome-DeepLearning
更多飞桨框架相关资料,请参考:飞桨深度学习平台
背景介绍
随着电子制造的发展,电子产品趋向于多功能,智能化和小型化。作为电子产品的重要精密部件,PCB电路板的质量直接影响产品的性能。因此,质量控制尤为重要。利用人工智能中计算机视觉技术,可以保障PCB板的生产质量。
数据集介绍
印刷电路板(PCB)瑕疵数据集:数据下载链接,是一个公共的合成PCB数据集,由北京大学发布,其中包含1386张图像以及6种缺陷(缺失孔,鼠咬伤,开路,短路,杂散,伪铜),用于检测、分类和配准任务。我们选取了其中适用于检测任务的693张图像,随机选择593张图像作为训练集,100张图像作为验证集。
任务详情
利用RCNN系列算法完成印刷电路板瑕疵检测。评估方法是使用IoU=0.5,area=all的mAP作为评价指标,得分=mAP * 100,范围[0,100]。
数据准备
首先将印刷电路板(PCB)瑕疵数据集与PaddleDetection代码解压到~/work/目录中:
本案例使用PaddleDetection 2.2版本。# 解压数据集
!tar -xf /home/aistudio/data/data52914/PCB_DATASET.tar -C ~/work/# 解压PaddleDetection源码
!unzip /home/aistudio/data/data112107/PaddleDetection2.2-PCB_fasterrcnn.zip -d ~/work/
环境安装
进行训练前需要安装PaddleDetection所需的依赖包,执行以下命令即可安装:%cd ~/work/PaddleDetection-release-2.2/
! pip install -r requirements.txt
! pip install pycocotools
数据集分析
在调整配置之前,请首先对数据有一个大概的了解。由于是个小数据,这里只简单分析了几项跟配置息息相关的内容,包括每个种类样本个数、每张图像上平均有几个目标、目标框长宽比分布、目标框占图像比例分布等。import json
from collections import defaultdict
import matplotlib.pyplot as plt
%matplotlib inline
with open("/home/aistudio/work/PCB_DATASET/Annotations/train.json") as f:
data = json.load(f)
imgs = {}
for img in data[‘images’]:
imgs[img[‘id’]] = {
‘h’: img[‘height’],
‘w’: img[‘width’],
‘area’: img[‘height’] * img[‘width’],
}
hw_ratios = []
area_ratios = []
label_count = defaultdict(int)
for anno in data[‘annotations’]:
hw_ratios.append(anno[‘bbox’][3]/anno[‘bbox’][2])
area_ratios.append(anno[‘area’]/imgs[anno[‘image_id’]][‘area’])
label_count[anno[‘category_id’]] += 1label_count, len(data[‘annotations’]) / len(data[‘images’])1. 从标签来看,总共6个类别。
2. 各类别之间的框数量相对较平均,不需要调整默认的分类损失和检测框回归损失。(如果类别之间相差较大,建议调整损失函数,如在分类、整体定位及精确定位中可以实现更平衡训练的BalancedL1Loss)
3. 平均每张图的框数量在4个左右,属于比较稀疏的检测,使用默认的需要保留的box的数目keep_top_k即可。
4. 多类别检测后处理使用MultiClassNMS。plt.hist(hw_ratios, bins=100, range=[0, 2])
plt.show()这是真实框的宽高比,可以看到大部分集中在1.0左右,但也有部分在0.51之间,少部分在1.252.0之间。虽说anchor会进行回归得到更加准确的框,但是一开始给定一个相对靠近的anchor宽高比会让回归更加轻松。这里使用默认的
[0.5, 1, 2]即可。plt.hist(area_ratios, bins=100, range=[0, 0.005])
plt.show()这是真实框在原图的大小比例,可以看到大部分框只占到了原图的0.1%,甚至更小,因此基本都是很小的目标,这个也可以直接看一下原图和真实框就能发现。
在本实验中,anchor_sizes设置为:anchor_sizes: [[32], [64], [128], [256], [512]]。
数据配置
本实验用到的数据配置如下:
metric: COCO # Label评价指标,coco IoU:0.5:0.95 num_classes: 6 # 类别数量 TrainDataset: !COCODataSet image_dir: images anno_path: Annotations/train.json dataset_dir: /home/aistudio/work/PCB_DATASET data_fields: ['image', 'gt_bbox', 'gt_class']#, 'is_crowd' evalDataset: !COCODataSet image_dir: images anno_path: Annotations/val.json dataset_dir: /home/aistudio/work/PCB_DATASET TestDataset: !ImageFolder anno_path: Annotations/val.json
其他配置介绍
预训练模型:
建议直接到PaddleDection的MODEL_ZOO文档中找相关的模型参数。预训练能大大缩短收敛时间。本实验预训练模型参数为https://paddledet.bj.bcebos.com/models/pretrained/ResNet50_cos_pretrained.pdparams/FPN通道数:
本实验FPN模块通道数默认是256通道。学习率为0.0025。衰减轮数milestones一般配置在max_iters的2/3和8/9处,尽量靠后。本案例epoch为24,
milestones: [16, 22]。数据增强:
这里使用的数据增强方式有RandomResize、RandomFlip、NormalizeImage。
如果启动环境的时候选择的是GPU,则执行下面的脚本进行训练:# GPU训练脚本
!CUDA_VISIBLE_DEVICES=0
!python3.7 -u tools/train.py -c /home/aistudio/work/PCB_faster_rcnn_r50_fpn_3x_coco.yml --eval如果启动环境的时候选择的是CPU,则执行下面的脚本进行训练:# CPU训练脚本
!python3.7 -u tools/train.py -c /home/aistudio/work/PCB_faster_rcnn_r50_fpn_3x_coco.yml --eval -o use_gpu=False
评估与预测
如果在训练中加了--eval参数,在模型训练完就可得到mAP指标,如果要对模型单独计算mAP,可以运行:
如果使用CPU进行评估,修改
use_gpu=False。%cd /home/aistudio/work/PaddleDetection-release-2.2
!python -u /home/aistudio/work/PaddleDetection-release-2.2/tools/eval.py -c /home/aistudio/work/PCB_faster_rcnn_r50_fpn_3x_coco.yml
-o weights=models/PCB_faster_rcnn_r50_fpn_3x_coco/best_model.pdparams use_gpu=True
模型推理,用训练出来的模型在一个PCB图像上进行测试。测试结果保存在work/PaddleDetection-release-2.1/output/04_missing_hole_10.jpg! python -u tools/infer.py -c /home/aistudio/work/PCB_faster_rcnn_r50_fpn_3x_coco.yml
–infer_img=…/PCB_DATASET/images/04_missing_hole_10.jpg
-o weights=models/PCB_faster_rcnn_r50_fpn_3x_coco/best_model.pdparams use_gpu=True推理结果可视化:%matplotlib inline
import matplotlib.pyplot as plt
import cv2
infer_img = cv2.imread(“output/04_missing_hole_10.jpg”)
plt.figure(figsize=(15, 10))
plt.imshow(cv2.cvtColor(infer_img, cv2.COLOR_BGR2RGB))
plt.show()
可优化方向
数据层面
数据增广(Mixup、AutoAugment、GridMask等)、测试时增强。
模型层面
预训练模型、backbone,fpn,head,后处理、正则化、损失函数(如Balanced L1 Loss)。
训练层面
学习率,优化器、参数更新策略。更多深度学习资源
一站式深度学习平台awesome-DeepLearning
深度学习入门课
深度学习百问

特色课

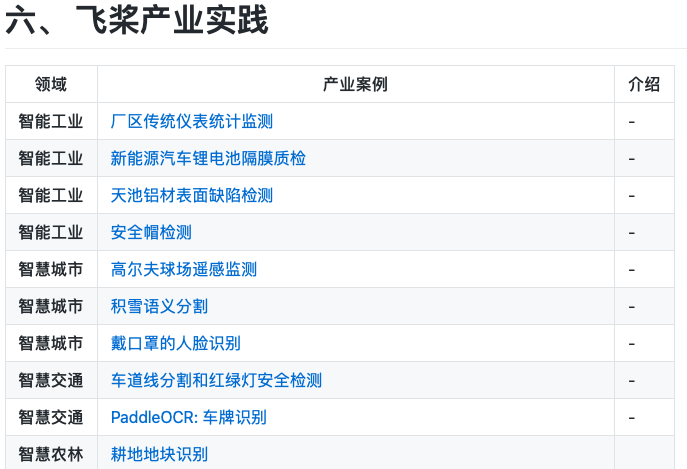
产业实践
PaddleEdu使用过程中有任何问题欢迎在awesome-DeepLearning提issue,同时更多深度学习资料请参阅飞桨深度学习平台。