1 项目说明
随着科技的发展,各种即时通讯早已是人类日常生活不可分割的一部分,而这一便捷服务的实现离不开各种通信塔。通信塔主要用于运营商、广播电视等部门架设信号发射天线或微波传输设备,对通信塔及时正确的维护是保障无线通信系统正常运行的必要手段。
在真实产业应用过程中,通信塔的外观会根据所处地貌、环境特点被设计成不同形态。不同类别塔的维护方式以及运营策略也均不相同,而传统的通信塔类别信息主要靠人工根据经验进行判断,这就会导致以下问题:
人工判断费时费力效率低下;
塔身外观种类多样,人工判断难免出错;
类别判断失误导致维修、运营策略不匹配,既耽误工时也影响企业信誉。
基于上述难点,我们与中国铁塔股份有限公司就通信塔识别项目开展了合作研发。经过多次业务场景讨论和模型效果验证,最终选用飞桨目标检测开发套件PaddleDetection中的全新的轻量级系列模型PP-PicoDet,该模型在移动端具有卓越的性能,成为全新SOTA轻量级模型。详细的技术细节可以参考arXiv技术报告。模型效果如 图1 所示。

最后将训练好的模型部署在Android移动端,部署教程参考Android部署教程,效果如 图2 所示。

项目带来的价值:
提高人工稽核的效率和准确度;
减少因为通信塔类别判断失误带来的额外运维成本。
如需更多技术交流与合作,欢迎扫码加入交流群:

2 安装说明
环境要求
PaddlePaddle >= 2.1.2
Python >= 3.5
PaddleSlim >= 2.1.1
PaddleLite >= 2.10
提供了修改配置文件的PaddleDetection代码,解压即可。!unzip -q PaddleDetection.zip# 如果想下载PaddleDetection源码,执行如下命令
#!git clone https://github.com/PaddlePaddle/PaddleDetection.git -b develop --depth 1# 安装其他依赖
%cd PaddleDetection
!pip install -r requirements.txt
#编译安装paddledet
!python setup.py install
!pip install paddleslim==2.1.1* 注:更多安装教程请参考安装文档
3 数据准备
本案例使用数据集来源于真实场景,因此不对外公开,我们仅提供24张图片,跑通流程,大家换成自己的数据集使用相同的处理步骤即可。该数据集包含8类,共14,433张图片,其中包含11,547张训练集图片,2,886张验证集图片,部分图片如 图3 所示:

如果数据集是COCO格式可以跳过该步骤。由于原始数据集格式不是COCO数据格式,我们需要处理为COCO数据格式进行训练。COCO数据标注是将所有训练图像的标注都存放到一个json文件中。数据以字典嵌套的形式存放。
json文件中包含以下key:
info,表示标注文件info。
licenses,表示标注文件licenses。
images,表示标注文件中图像信息列表,每个元素是一张图像的信息。如下为其中一张图像的信息:
{ 'license': 3, # license 'file_name': '000000391895.jpg', # file_name # coco_url 'coco_url': 'http://images.cocodataset.org/train2017/000000391895.jpg', 'height': 360, # image height 'width': 640, # image width 'date_captured': '2013-11-14 11:18:45', # date_captured # flickr_url 'flickr_url': 'http://farm9.staticflickr.com/8186/8119368305_4e622c8349_z.jpg', 'id': 391895 # image id }annotations,表示标注文件中目标物体的标注信息列表,每个元素是一个目标物体的标注信息。如下为其中一个目标物体的标注信息:
{ 'segmentation': # 物体的分割标注 'area': 2765.1486500000005, # 物体的区域面积 'iscrowd': 0, # iscrowd 'image_id': 558840, # image id 'bbox': [199.84, 200.46, 77.71, 70.88], # bbox [x1,y1,w,h] 'category_id': 58, # category_id 'id': 156 # image id }
源数据格式为VOC格式,存储格式如下:
dataset/ ├── Annotations │ ├── xxx1.xml │ ├── xxx2.xml │ ├── xxx3.xml │ | ... ├── Images │ ├── xxx1.jpg │ ├── xxx2.jpg │ ├── xxx3.jpg │ | ... ├── label_list.txt (必须提供) ├── train.txt (训练数据集文件列表, ./Images/xxx1.jpg ./Annotations/xxx1.xml) ├── valid.txt (测试数据集文件列表)
我们通过如下命令将图片格式处理为COCO格式,执行一次即可。 # 首先解压数据集
%cd /home/aistudio
!unzip -q dataset.zip
%cd PaddleDetection/# 训练集
‘’’
params
dataset_type: 原数据格式
voc_anno_dir: xml标注文件夹
voc_anno_list: 训练集列表
voc_label_list: 类别标签
voc_out_name: 输出json文件
‘’’
!python tools/x2coco.py
–dataset_type voc
–voc_anno_dir /home/aistudio/dataset/Annotations/
–voc_anno_list /home/aistudio/dataset/train.txt
–voc_label_list /home/aistudio/dataset/label_list.txt
–voc_out_name /home/aistudio/dataset/voc_train.json# 验证集
!python tools/x2coco.py
–dataset_type voc
–voc_anno_dir /home/aistudio/dataset/Annotations/
–voc_anno_list /home/aistudio/dataset/val.txt
–voc_label_list /home/aistudio/dataset/label_list.txt
–voc_out_name /home/aistudio/dataset/voc_val.json代码执行完成后数据集文件组织结构为:
├── voc_train.json ├── voc_val.json │ | ... ├── Images │ ├── 000000000009.jpg │ ├── 000000580008.jpg
4 模型选择
因为要部署在移动端,且保证速度快和精度高,因此我们选择PaddleDetection提出的全新轻量级系列模型PP-PicoDet,模型有如下特点:
更高的mAP: 第一个在1M参数量之内mAP(0.5:0.95)超越30+(输入416像素时)。
更快的预测速度: 网络预测在ARM CPU下可达150FPS。
部署友好: 支持PaddleLite/MNN/NCNN/OpenVINO等预测库,支持转出ONNX,提供了C++/Python/Android的demo。
先进的算法: 我们在现有SOTA算法中进行了创新, 包括:ESNet, CSP-PAN, SimOTA等等。
PP-PicoDet提供了多种在COCO数据上的预训练模型,如下图所示:
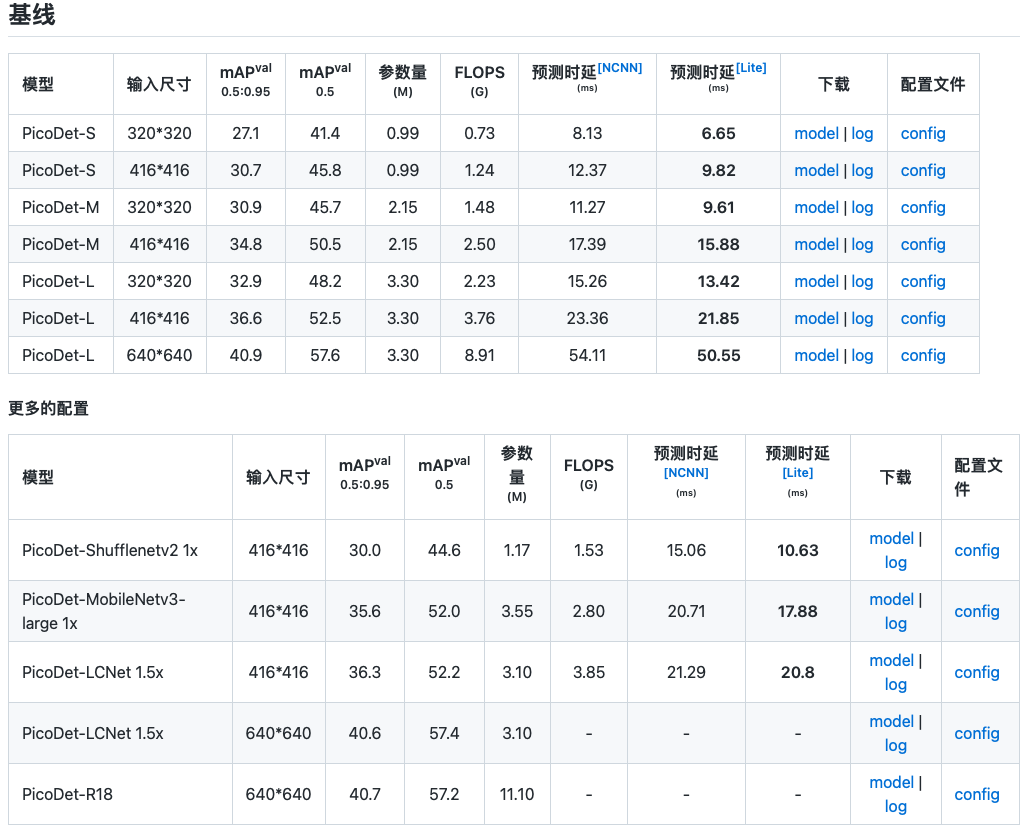
5 模型训练
本项目采用PP-PicoDet作为铁塔识别的模型,模型训练需要经过如下环节:

首先修改configs/datasets/coco_detection.yml
数据集包含的类别数:num_classes
包含训练集、验证集、测试集的图片路径image_dir、标注json文件路径anno_path、数据集路径dataset_dir
然后修改configs/picodet/picodet_l_640_coco.yml
预训练模型:pretrain_weights
训练超参数:epoch、batch_size、base_lr
最后启动训练
PaddleDetection提供了单卡/多卡训练模型,满足用户多种训练需求,具体代码如下:# 单卡GPU上训练
!export CUDA_VISIBLE_DEVICES=0 #windows和Mac下不需要执行该命令
!python tools/train.py -c configs/picodet/picodet_l_640_coco.yml --eval
#多卡GPU上训练
#!export CUDA_VISIBLE_DEVICES=0,1,2,3
#!python -m paddle.distributed.launch --gpus 0,1,2,3 tools/train.py
#-c configs/picodet/picodet_l_640_coco.yml
6 模型评估
使用训练好的模型在验证集上进行评估,具体代码如下:#评估
!export CUDA_VISIBLE_DEVICES=0
‘’’
-c:指定模型配置文件
-o weights:加载训练好的模型
‘’’
!python tools/eval.py -c configs/picodet/picodet_l_640_coco.yml
-o weights=output/picodet_l_640_coco/model_final.pdparams使用用全量数据集上训练的模型,在包含2,886张图片的验证集上评估,效果如下,mAP(0.5)=90.6%:
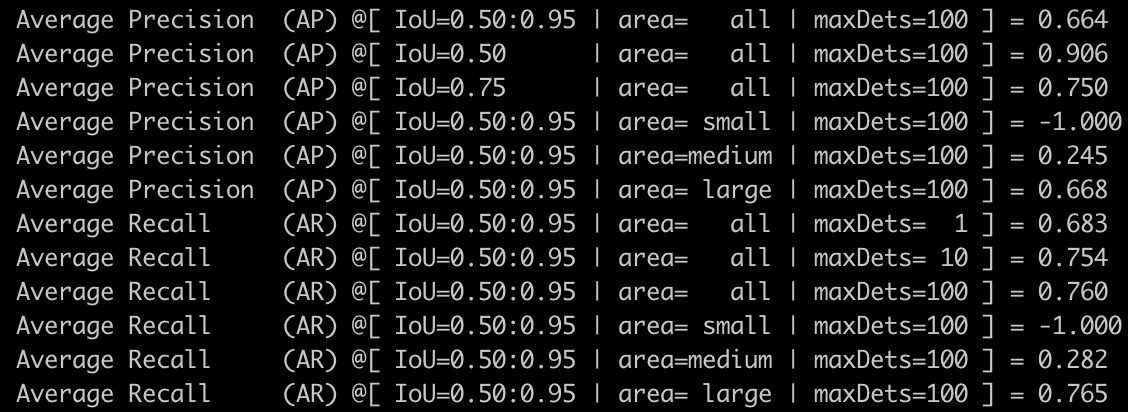
7 模型预测
加载训练好的模型,置信度阈值设置为0.5,执行下行命令对验证集或测试集图片进行预测:!export CUDA_VISIBLE_DEVICES=0
‘’’
-c:指定模型配置文件
–infer_img:测试图片
–output_dir:结果输出位置
–draw_threshold:置信度阈值
-o weights:加载训练好的模型
‘’’
!python3.7 tools/infer.py -c configs/picodet/picodet_l_640_coco.yml
–infer_img=/home/aistudio/dataset/Images/a_01.jpg
–output_dir=infer_output/
–draw_threshold=0.5
-o weights=output/picodet_l_640_coco/model_final使用全量数据训练的模型预测,可视化预测结果示例如 图7 所示,可以看出预测结果(黄色框)和真实类别(红色框)相同,表示模型能够正确识别铁塔类别:

8 模型导出
在模型训练过程中保存的模型文件是包含前向预测和反向传播的过程,在实际的工业部署则不需要反向传播,因此需要将模型进行导成部署需要的模型格式。 执行下面命令,即可导出模型!export CUDA_VISIBLE_DEVICES=0
!python tools/export_model.py
-c configs/picodet/picodet_l_640_coco.yml
-o weights=output/picodet_l_640_coco/model_final.pdparams
–output_dir=inference_model预测模型会导出到inference_model/目录下,包括model.pdmodel、model.pdiparams、model.pdiparams.info和infer_cfg.yml四个文件,分别表示模型的网络结构、模型权重、模型权重名称和模型的配置文件(包括数据预处理参数等)的流程配置文件。
更多关于模型导出的文档,请参考模型导出文档
9 模型推理
在终端输入以下命令进行预测,详细教程请参考Python端预测部署:!export CUDA_VISIBLE_DEVICES=0
‘’’
–model_dir: 上述导出的模型路径
–image_file:需要测试的图片
–image_dir:也可以指定要测试的文件夹路径
–device:运行时的设备,可选择CPU/GPU/XPU,默认为CPU
–output_dir:可视化结果保存的根目录,默认为output/
‘’’
!python deploy/python/infer.py
–model_dir=./inference_model/picodet_l_640_coco
–image_file=/home/aistudio/dataset/Images/a_01.jpg
–device=GPU
10 模型优化
本小节侧重展示在模型迭代过程中优化精度的思路,在本案例中,尝试以下模型优化策略,
预训练模型:使用预训练模型可以有效提升模型精度,PP-PicoDet模型提供了在COCO数据集上的预训练模型
修改loss:将目标检测中的GIOU loss改为DIOU loss
修改lr:调整学习率,这里将学习率调小一半
修改lr再训练:当模型不再提升,可以加载训练好的模型,把学习率调整为十分之一,再训练。
有些优化策略获得了精度收益,而有些没有。因为PP-PicoDet模型已经采用多种优化策略,因此除了第2种增加COCO预训练模型,其它几种策略没有精度收益。虽然这些策略在这个模型没起到效果,但是可能在其他模型中有效。将训练好的模型提供给大家,存放在:/home/aistudio/work/文件夹内。
我们所有的模型都在在麒麟980上测试,速度测试教程,实验结果如下:
| 序号 | 模型 | 推理时间/ms | mAP0.5 |
|---|---|---|---|
| 1 | PP-PicoDet(baseline) | - | 90.6% |
| 2 | PP-PicoDet+COCO预训练 | 125 | 94.7% |
| 3 | PP-PicoDet+COCO预训练+修改loss | - | 94.5% |
| 4 | PP-PicoDet+COCO预训练+调小lr | - | 94.7% |
| 5 | PP-PicoDet+COCO预训练+修改lr再训练 | - | 94.9% |
11 模型量化训练
通过模型量化可以提升模型速度。
我们在【PP-PicoDet+COCO预训练】模型基础上进行量化训练,执行如下代码开始量化训练:
注:1)我们需要修改’configs/slim/quant/picodet_s_quant.yml’量化配置文件,将pretrain_weights参数改为量化前训练好的模型。
2)如果模型报错,调小picodet_s_quant.yml文件中的batch_size
#单卡训练
‘’’
-c: 指定模型配置文件
–slim_config: 量化配置文件
‘’’
!export CUDA_VISIBLE_DEVICES=0
!python tools/train.py
-c configs/picodet/picodet_l_640_coco.yml
–slim_config configs/slim/quant/picodet_s_quant.yml
#多卡训练
#!export CUDA_VISIBLE_DEVICES=0,1,2,3
#!python -m paddle.distributed.launch --gpus 0,1,2,3 tools/train.py
#-c configs/picodet/picodet_l_640_coco.yml
#–slim_config configs/slim/quant/picodet_s_quant.yml量化后的模型mAP(0.5)=94.5%,在精度下降幅度较小的情况下,速度提升了37%,因此最终可采用这个策略。
| 序号 | 模型 | 推理时间/ms | mAP0.5 |
|---|---|---|---|
| 2 | PP-PicoDet+COCO预训练 | 125 | 94.7% |
| 6 | PP-PicoDet+COCO预训练+量化 | 78 | 94.5% |
!export CUDA_VISIBLE_DEVICES=0
!python tools/eval.py -c configs/picodet/picodet_l_640_coco.yml
–slim_config configs/slim/quant/picodet_s_quant.yml
-o weights=output/picodet_s_quant/model_final# 模型导出
!export CUDA_VISIBLE_DEVICES=0
!python tools/export_model.py
-c configs/picodet/picodet_l_640_coco.yml
–slim_config configs/slim/quant/picodet_s_quant.yml
-o weights=output/picodet_s_quant/model_final.pdparams
–output_dir=inference_model
#将inference模型配置转化为json格式
!python deploy/lite/convert_yml_to_json.py inference_model/picodet_s_quant/infer_cfg.yml
12 Android APP
基于Paddle Lite将PicoDet模型部署到手机,提供铁塔识别Android demo,详细教程参考Android部署教程。
更多资源
更多深度学习知识、产业案例、面试宝典等,请参考:awesome-DeepLearning
更多PaddleDetection使用教程,包含目标检测、实例分割、跟踪等算法,请参考:PaddleDetection
更多PaddleSlim使用教程,包含剪裁、量化、蒸馏、和模型结构搜索等模型压缩策略,请参考:PaddleSlim
更多Paddle Lite使用教程,包含多种终端设备的部署等,请参考:PaddleLite
飞桨框架相关资料,请参考:飞桨深度学习平台